这是最近在做的马太效应数字画像实验中语义迁移实验部分的流程和总结
数据集

在谷歌图书上搜索关键词,然后对得到的匹配结果语段进行爬虫操作,作为后续的数据集
爬虫
from lxml import etree
import requests
import sys, time
import random
import xlwt
from selenium import webdriver
from fake_useragent import UserAgent
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.chrome.service import Service
import os
from selenium.webdriver.common.keys import Keys
from time import sleep
# 随机使用useragent
def getUseragent():
myuseragent = UserAgent().chrome.split()
myuseragent[-2] = 'Chrome/108.0.5359.95' #必须要改成这个版本的,不然google的版本太低无法爬取
myuseragent = ' '.join(myuseragent)
# print(myuseragent)
return myuseragent
# 随机获取不同的google域名
def google_main():
filepath = "./google main.txt"
googleUrl = [line.strip() for line in open(filepath, 'r', encoding='utf-8').readlines()]
url = random.choice(googleUrl) # 随机抽取
return url
# 获取每个图书详情页面的内容
def crawling_paragraph(urls, workbook, worksheet, row):
for i in range(len(urls)):
url = urls[i]
# year = years[i]
driver.get(url)
driver.implicitly_wait(15)
# button:继续使用Google搜索前的须知
# try:
# driver.find_element_by_xpath("//button[@aria-label='同意 Google 出于所述的目的使用 Cookie 和其他数据']").click()
# except:
# print("success")
# try:
# driver.find_element_by_xpath("//button[@aria-label='全部接收']").click()
# except:
# print("success")
html = driver.page_source
j = 7
while (1):
try:
k = 1
input_text_list=[]
while(1):
input_xpath="/html/body/div[" + str(j) + "]/div[2]/b["+str(k)+"]/text()" # 被截断的检索关键词
input_text_data = etree.HTML(html).xpath(input_xpath)
# print(input_text_data)
# print("success-this")
if input_text_data!=[]:
input_text_list.append(input_text_data[0])
k+=1
else:
break;
# print(input_text_list)
paragraph_xpath = "/html/body/div[" + str(j) + "]/div[2]/text()"
paragraph_data = etree.HTML(html).xpath(paragraph_xpath)
if paragraph_data == []:
break;
# print(paragraph_data)
paragraph = paragraph_data[0] # 爬取得到的上下文语段
for x in range(len(paragraph_data)-1):
# if x != 0:
# # paragraph = paragraph + ("virus" + paragraph_data[x])
# paragraph = paragraph + ("clade virus" + paragraph_data[x+1])
# else:
paragraph = paragraph + input_text_list[x] + paragraph_data[x+1]
print(paragraph) # 获得上下文语段
# 保存数据
# worksheet.write(row, 0, year, style) # 带样式的写入
worksheet.write(row, 0, paragraph, style)
workbook.save('data.xls') # 保存文件
except:
break
j += 1
row += 1
# driver.quit() # 爬虫完毕,关掉浏览器
return row
# 获取每个图书的具体地址
def crawling(searchkey, start_year,end_year,page, workbook, worksheet, row):
all_url = []
googleUrl = google_main()
# 可看内容不限,爬取的数据更多
url = "https://" + googleUrl + "/search?q=" + searchkey + "&tbs=cdr:1,cd_min:1/1/" + str(
start_year) + ",cd_max:12/31/" + str(
end_year) + ",bkv:a&tbm=bks&sxsrf=ALiCzsZ_FgzKNNsCQ-GjEDgepxzYHHit-Q:1667459481738&ei=mWljY7jFLJGO-Aau1r6gAQ&start=" + str(
(page - 1) * 10) + "&sa=N&ved=2ahUKEwj49dfQupH7AhURB94KHS6rDxQ4UBDy0wN6BAgOEAQ&biw=1325&bih=774&dpr=1.5"
driver.get(url)
# 因为谷歌页面是动态加载的,需要给予页面加载时间
driver.implicitly_wait(15)
sleep(15)
# button:继续使用Google搜索前的须知
# try:
# driver.find_element_by_xpath("//button[@aria-label='同意 Google 出于所述的目的使用 Cookie 和其他数据']").click()
# except:
# print("success")
# try:
# driver.find_element_by_xpath("//button[@aria-label='全部接收']").click()
# # driver.find_element_by_xpath("//button[@class='Gfzyee VDgVie DKlyaf Loxgyb'][1]/div[@class='fSXkBc']").click()
# except:
# print("success")
html = driver.page_source
# print(html)
try: # 检索到最后一页不足十本书
for i in range(1,11,1): #循环一个页面上的十本书籍
jurisdiction_xpath = "/html/body[@id='gsr']/div[@id='main']/div[@id='cnt']/div[@id='rcnt']/div[@id='center_col']/div[@id='res']/div[@id='search']/div/div[@id='rso']/div[@class='MjjYud']["+str(i)+"]/div[@class='Yr5TG']/div[@class='bHexk Tz5Hvf']/div[@class='N96wpd']/span[2]/text()"
jurisdiction = etree.HTML(html).xpath(jurisdiction_xpath)
# print("jurisdiction=",jurisdiction)
if jurisdiction == []: # 空列表,说明可以详细爬取
href_xpath = "/html/body[@id='gsr']/div[@id='main']/div[@id='cnt']/div[@id='rcnt']/div[@id='center_col']/div[@id='res']/div[@id='search']/div/div[@id='rso']/div[@class='MjjYud'][" + str(
i) + "]/div[@class='Yr5TG']/div[@class='bHexk Tz5Hvf']/a/@href"
href_data = etree.HTML(html).xpath(href_xpath)
# print(href_data[0])
href_data = href_data[0].split('?')
googleUrl = google_main()
href_data[0] = "https://" + googleUrl + "/books?" + href_data[1]
# print(href_data[0])
all_url.append(href_data[0])
elif jurisdiction[0] == "阅读内容摘录": # 没有查看的权限,只有预览,将预览进行保存
text_xpath = "/html/body[@id='gsr']/div[@id='main']/div[@id='cnt']/div[@id='rcnt']/div[@id='center_col']/div[@id='res']/div[@id='search']/div/div[@id='rso']/div[@class='MjjYud']["+str(i)+"]/div[@class='Yr5TG']/div[@class='bHexk Tz5Hvf']/div[@class='cmlJmd ETWPw']/span/span/text()"
text = etree.HTML(html).xpath(text_xpath)
# 检索关键词是被截断的,需要额外增加
k = 1
keywords_list = []
while(1):
keywords_xpath = "/html/body[@id='gsr']/div[@id='main']/div[@id='cnt']/div[@id='rcnt']/div[@id='center_col']/div[@id='res']/div[@id='search']/div/div[@id='rso']/div[@class='MjjYud']["+str(i)+"]/div[@class='Yr5TG']/div[@class='bHexk Tz5Hvf']/div[@class='cmlJmd ETWPw']/span/span/em["+str(k)+"]/text()"
data = etree.HTML(html).xpath(keywords_xpath)
if data != []:
keywords_list.append(data[0])
k+=1
else:
break
if len(text)==1:
paragrapg = keywords_list[0] + text[0]
else:
paragrapg = text[0]
for x in range(len(text)-1):
paragrapg = paragrapg + keywords_list[x] + text[x+1]
print(paragrapg)
worksheet.write(row, 0, paragrapg, style)
workbook.save('data.xls') # 保存文件
row += 1
elif jurisdiction[0] == "无预览": # 直接跳过
continue
except:
print("finish")
# driver.quit() # 爬虫完毕,关掉浏览器
return all_url,row
# 初始化一个对象,ChromeOptions代表浏览器的操作
options = Options() #这是一个空对象
options.add_experimental_option("excludeSwitches", ["enable-automation"])
options.add_experimental_option('useAutomationExtension', False)
options.add_argument('lang=zh-CN,zh,zh-TW,en-US,en')
# 关闭webrtc
preferences = {
"webrtc.ip_handling_policy": "disable_non_proxied_udp",
"webrtc.multiple_routes_enabled": False,
"webrtc.nonproxied_udp_enabled": False
}
options.add_experimental_option("prefs", preferences)
# 随机产生user_agent
options.add_argument('User-Agent=%s'%getUseragent())
# 使用socks代理
# options.add_argument("proxy-server=socks5://127.0.0.1:4781")
# 去掉webdriver痕迹
options.add_argument("disable-blink-features=AutomationControlled")
#加载cookies中已经保存的账号和密码,运行的时候要关掉所有谷歌网站
options.add_argument(r"user-data-dir=C:\Users\cy111\AppData\Local\Google\Chrome\User Data")
#设置谷歌浏览器的页面无可视化
# options.add_argument('--headless')
# options.add_argument('--disable-gpu')
# 插件使用
driver_path = r'C:\Program Files\Google\Chrome\Application\chromedriver.exe'
driver = webdriver.Chrome(options = options,executable_path = driver_path)
global row
row = 0
workbook = xlwt.Workbook(encoding = 'ascii')
worksheet = workbook.add_sheet('Sheet1')
style = xlwt.XFStyle() # 初始化样式
font = xlwt.Font() # 为样式创建字体
font.name = 'Times New Roman'
style.font = font # 设定样式
# 一年一年搜,检索到的结果最多
start_years = [i for i in range(1885,1900)]
end_yeats = [i for i in range(1885,1900)]
key = '\"serendipity\"'
for start,end in zip(start_years,end_yeats):
start_year = start
end_year = end
original_row = 0
wrong = 0
page = 1
while(1):
try:
all_url,row = crawling(key,start_year,end_year,page, workbook, worksheet, row)
# print(all_year)
print(all_url)
if len(all_url)>0:
row = crawling_paragraph(all_url, workbook, worksheet, row)
print("row=",row)
page += 1
# 两次网页都没有爬取出来,break
if original_row==row:
wrong+=1
if wrong==2:
break
original_row = row
except:
break
数据预处理
处理语料(数据清洗+分词+去停用词)
import pandas as pd
import xlrd #读取excel数据
import re
import nltk
nltk.download('punkt')
nltk.download('wordnet')
nltk.download('averaged_perceptron_tagger')
nltk.download('omw-1.4')
from nltk.tokenize import MWETokenizer
import re
import sys, time
from matplotlib import pyplot as plt
import numpy as np
from sklearn.decomposition import PCA
from scipy.linalg import orthogonal_procrustes
from nltk.stem.porter import PorterStemmer
from nltk.stem import WordNetLemmatizer
from nltk import word_tokenize, pos_tag
from nltk.corpus import wordnet
from nltk.stem import WordNetLemmatizer
from nltk.stem import PorterStemmer
from mpl_toolkits import mplot3d
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
from mpl_toolkits.mplot3d.art3d import Poly3DCollection
import xlrd #读取excel数据
def stopwordslist(filepath):
"""
从文件导入停用词表
:param filepath: 停用词文件的地址
:return: 停用词列表
"""
stopwords=[line.strip() for line in open(filepath,'r',encoding='utf-8').readlines()]
return stopwords
# 获取单词的词性
def get_wordnet_pos(tag):
if tag.startswith('J'):
return wordnet.ADJ
elif tag.startswith('V'):
return wordnet.VERB
elif tag.startswith('N'):
return wordnet.NOUN
elif tag.startswith('R'):
return wordnet.ADV
else:
return None
def preprocess(doc_set,stopwords):
"""
处理语料(数据清洗+分词+去停用词)
:param doc_set: 语料库的数据,类型为list
:param stopwords: 停用词列表
:return: 处理好的文章关键词
"""
texts = []#每篇文章关键词
for doc in doc_set:
doc=doc.lower()
# 数据清洗,删除数字以及特殊符号
cop=re.compile('\d')
cleaned_doc=cop.sub('',doc)
cop=re.compile('[.:/()\?!\(\)\[\]\{\}\*\+\\\|\"\<\>,~@#$%^&\-+=;\'\`“”—_·]')
cleaned_doc=cop.sub('',cleaned_doc)
# 小写化
cleaned_doc=cleaned_doc.lower()
# 分词
# tokenizer = MWETokenizer([('associated', 'with', 'a', 'chance', 'or', 'accidental', 'factor')
# ,('discoveries', 'accidentally')
# ,('accidental', 'sagacity')
# ,('prepared', 'mind')
# ,('associated', 'with', 'chance')]
# ,separator='_')
tokenizer = MWETokenizer([('serendipitous', 'discovery')
,('the','happy','faculty')
,('the', 'result', 'of', 'an', 'accident', 'or', 'chance')
,('accidental', 'sagacity')
,('prepared', 'mind')
,('associated', 'with', 'chance')]
,separator='_')
doc_cut=tokenizer.tokenize(nltk.word_tokenize(cleaned_doc))
# doc_cut=nltk.word_tokenize(cleaned_doc)
# print(doc_cut)
# 获取词的词性后进行词形还原
tagged_sent = pos_tag(doc_cut)
wnl = WordNetLemmatizer()
lemmas_sent = [] # 词形还原后的结果
for tag in tagged_sent:
wordnet_pos = get_wordnet_pos(tag[1]) or wordnet.NOUN
lemmas_sent.append(wnl.lemmatize(tag[0], pos=wordnet_pos)) # 词形还原
# 去停用词
text_list = [word for word in lemmas_sent if word not in stopwords and len(word)>2 and len(word)<80]
# print(text_list)
texts.append(text_list)
return texts
stopwords = stopwordslist(r"stopwords_English+Latin.txt")
# year = "1885-1945"
year = "1945-2020"
doc_set = []
workbook = xlrd.open_workbook("./serendipity.xlsx")
sheet = workbook.sheet_by_name(year)
for index in range(sheet.nrows):
doc_set.append(sheet.row_values(index)[0])
texts = preprocess(doc_set, stopwords)
print(texts)
t=''
j=0
with open (year+'.txt','w',encoding='utf-8') as q:
for i in texts:
for e in range(len(texts[j])):
t=t+str(i[e])+' '
j+=1
q.write(t.strip(' '))
q.write('\n')
t=''
词向量训练
使用Word2Vec对1885-1945、1945-2020两个时间段的文本数据进行训练,得到词向量
使用CADE对两个时间段的词向量进行对齐,使其能相互比较
CADE:
Di Carlo, V., Bianchi, F., & Palmonari, M. (2019). Training Temporal Word Embeddings with a Compass. Proceedings of the AAAI Conference on Artificial Intelligence, 33(01), 6326-6334. https://doi.org/10.1609/aaai.v33i01.33016326

可视化
输出语料库中与“serendipity”语义最相近的前9个词,对词向量进行三维可视化

结论
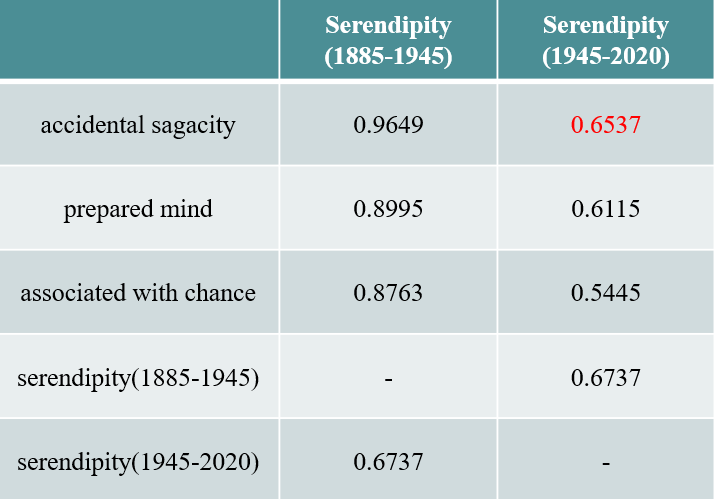
两个不同阶段的serendipity语义相似度为0.6737,说明1945年的miscredit对term的语义改变有一定的影响。
但两个时间阶段中serendipity与accidental sagacity的语义相似度都是最高的,且prepared mind、 associated with chance在这两个阶段的语义相似度排名并没有改变,这也进一步验证了这两个阶段的语义由于miscredit的出现产生了一些语用上的迁移,但语义的主体并没有太大的变动,由Horace Walpole第一次提出的“accidental sagacity”语义内涵并没有产生较大的变动。
第二个阶段出现了更多的语义干扰项,所以语义低了后面一个阶段出现的同义词多了,就出现了分流,所以语义低了。
论文总结:
