研究过程涉及的模型如下:
第一类模型:WordNet、Word2Vec、GloVe、fastText
第二类模型:ELMo、GPT-2、BERT、BioBERT、SciBERT、ClinicalBERT、BlueBERT、 PubMedBERT
实验需考虑问题:
是否有模型可以处理多语言
哪个模型对同义词的语义相似度计算更为准确
实验模型输入:
五个词——German measles,Rubella,Rötheln,Morbilli,Rubeola
第一类模型
WordNet
传统词典一般都是按字母顺序组织词条信息的,这样的词典在解决用词和选义问题上是有价值的。然而,它们有一个共同的缺陷,就是忽略了词典中同义信息的组织问题。
WordNet最具特色之处是根据词义而不是词形来组织词汇信息。可以说WordNet是一部语义词典。
其将词汇分为五大类:名词、动词、形容词、副词和虚词。语义关系包括上下位关系,同义关系,反义关系。
使用WordNet词典,使用的工具是nltk,利用里面自带的相似度(非余弦相似度)来计算词义相似度。
基于路径的方法:



基于互信息的方法:
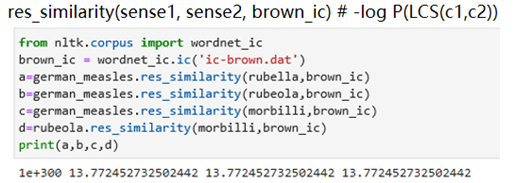
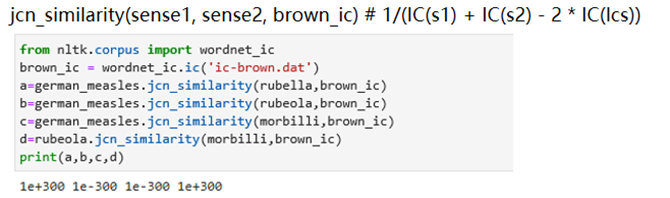
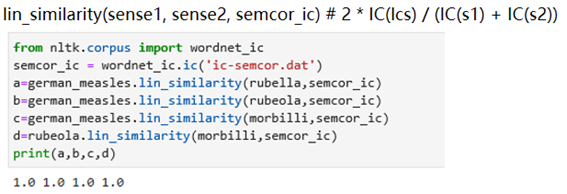
实验结论
(1)WordNet在处理同义词词集时无法处理德语的词性,会报错
(2)经过实验发现六种方法都没法处理德语词汇,并且在出现2-gram的词汇German measles时无法处理
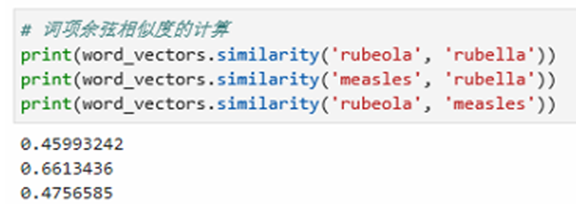
Word2Vec
Word2Vec,是一群用来产生词向量的相关模型。这些模型为浅而双层的神经网络,用来训练以重新建构语言学之词文本。网络以词表现,并且需猜测相邻位置的输入词,在Word2Vec中词袋模型假设下,词的顺序是不重要的。训练完成之后, Word2Vec模型可用来映射每个词到一个向量,该向量为神经网络之隐藏层。
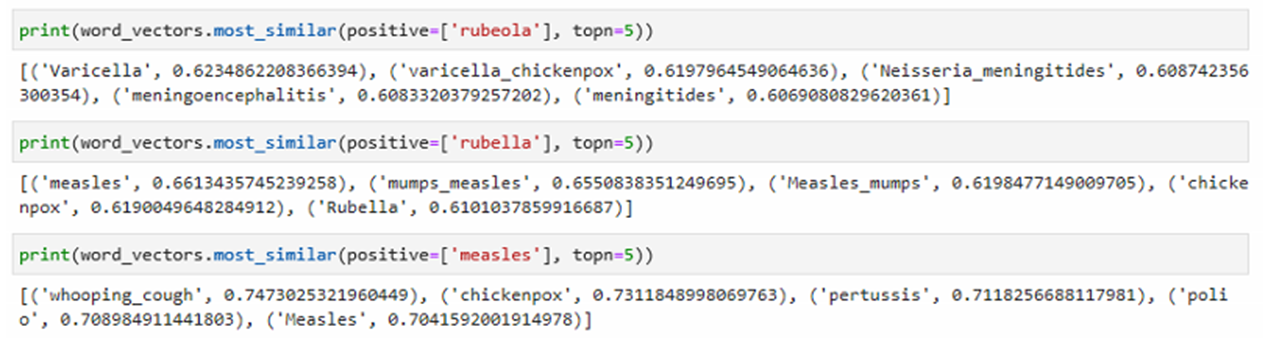
实验结论
(1)WordNet在处理同义词词集时无法处理德语的词性,会报错
(2)经过实验发现六种方法都没法处理德语词汇,并且在出现2-gram的词汇German measles时无法处理
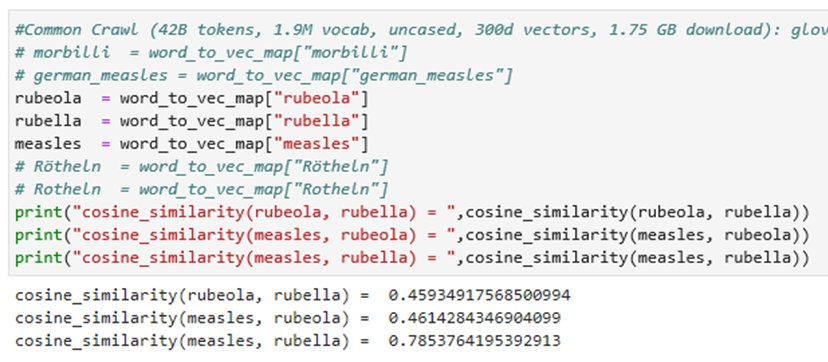
GloVe
GloVe是一种用于获取词汇向量表示的无监督学习算法。 对来自语料库的聚合全局字词同现统计进行训练,并且所得到的表示展示了词向量空间的线性子结构。
GloVe与Word2Vec,两个模型都可以根据词汇的共现(co-occurrence)信息,将词汇编码成一个向量(所谓共现,即语料中词汇一块出现的频率)。两者最直观的区别在于,Word2Vec是predictive模型,而GloVe是count-based模型。
Count-based模型,如GloVe,本质上是对共现矩阵进行降维。首先,构建一个词汇的共现矩阵,每一行是一个word,每一列是context。共现矩阵就是计算每个word在每个context出现的频率。由于context是多种词汇的组合,其维度非常大,我们希望像network embedding一样,在context的维度上降维,学习word的低维表示。这一过程可以视为共现矩阵的重构问题,即reconstruction loss。

实验结论
该预训练模型对于father\mother\rome\ball等常见词可以较好的得到词汇间的相关度,但是对于一些不太常见词就很难进行计算会报错,只能得到rubeola, rubella, measles之间的相似度。
(效果基本和Word2Vec类似)
fastText
fastText是Facebook Research在2016年开源的一个词向量及文本分类工具。fastText算法是Word2Vec的一种衍生模型。
Facebook 通过将词语内部的构词信息引人 Skip-Gram 模型,得到的 fastText 可以为任意词语构造词向量,而不要求该词语一定得出现在语料库中。但是,无论是 Word2Vec 还是 fastText,都无法解决一词多义的问题。
fastText最大的特点是模型简单,只有一层的隐层以及输出层,因此训练速度非常快,在普通的CPU上可以实现分钟级别的训练,比深度模型的训练要快几个数量级。


实验结论
基于该模型得到german measles与另外五个词汇进行相似度的比较,最后得到相似度从大到小的结论为morbilli,rotheln,rötheln,rubella,rubeola,可见fastText对于同义词间计算相似度效果并不理想