研究过程涉及的模型如下:
第一类模型:WordNet、Word2Vec、GloVe、fastText
第二类模型:ELMo、GPT-2、BERT、BioBERT、SciBERT、ClinicalBERT、BlueBERT、 PubMedBERT
实验需考虑问题:
是否有模型可以处理多语言
哪个模型对同义词的语义相似度计算更为准确
实验模型输入:
五个词——German measles,Rubella,Rötheln,Morbilli,Rubeola
模型与实验总结

实验方法确定
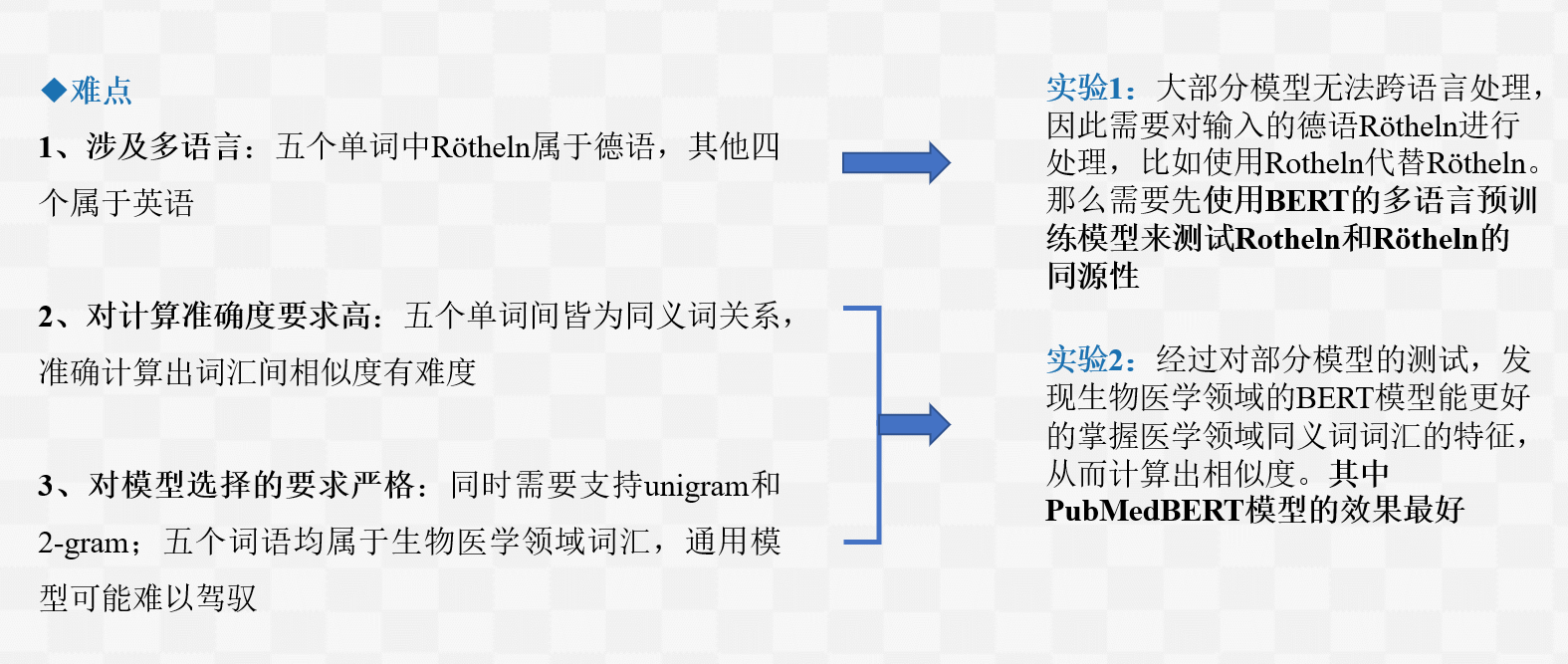
实验1 Rotheln和Rötheln的同源性测试
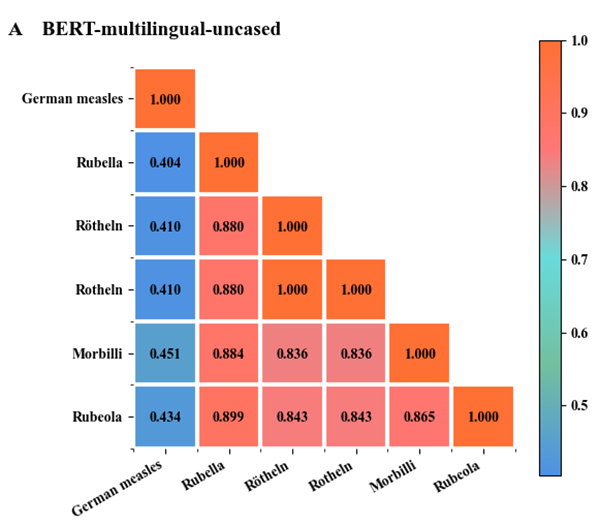
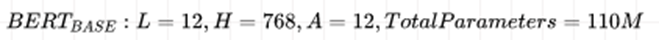
bert-base-multilingual-uncased预训练模型属于BERT预训练模型,这个模型是在多语言数据集上经过训练的,支持英语、法语、荷兰语、德语、意大利语以及西班牙语等100多种语言。
通过实验可以发现在多语言预训练模型中Rotheln和Rötheln的相似度为1,因此两者同源。在接下来计算相似度的单语言模型中,可以用Rotheln代替Rötheln。
实验2 词汇语义相似度计算
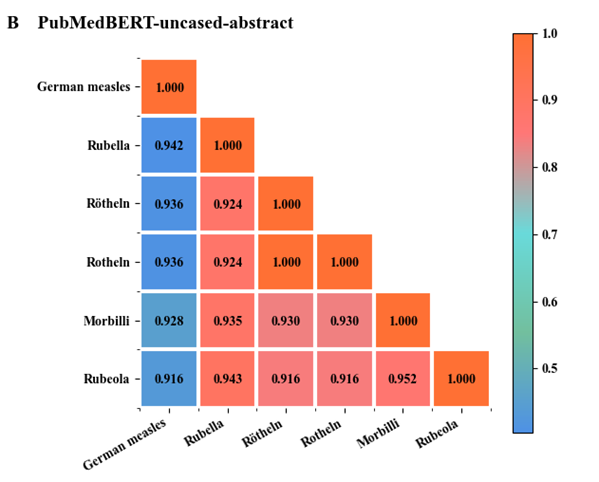
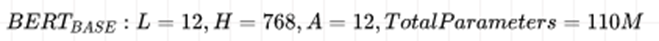
PubMedBERT-uncased-abstract预训练模型语料库包含1400万篇摘要,其中包含30亿个单词(21 GB),还通过添加PubMed Central的全文文章来对另一个版本的PubMedBERT进行预训练,使预训练语料库大幅增加至168亿字(107 GB)。
通过实验发现German measles与其他词汇的语义相似度从高到低分别为Rubella,Rötheln(Rotheln),Morbilli,Rubeola,其中Rubella的语义相似度最高
Case Study
