研究过程涉及的模型如下:
第一类模型:WordNet、Word2Vec、GloVe、fastText
第二类模型:ELMo、GPT-2、BERT、BioBERT、SciBERT、ClinicalBERT、BlueBERT、 PubMedBERT
实验需考虑问题:
是否有模型可以处理多语言
哪个模型对同义词的语义相似度计算更为准确
实验模型输入:
五个词——German measles,Rubella,Rötheln,Morbilli,Rubeola
第二类模型
ELMo
华盛顿大学提出了 ELMo,即一个在大规模纯文本上训练的双向 LSTM 语言模型。ELMo 通过读入上文来预测当前单词的方式为词嵌人引入了上下文信息。Zalando Research 的研究人员则将这一方法应用到了字符级别,得到了上下文字符串嵌入,其标注器取得了目前最先进的准确率,效果好,在大部分任务上都较传统模型有提升。
传统的预训练词向量只能提供一层表征,而且词汇量受到限制。ELMo所提供的是character-level的表征,对词汇量没有限制。
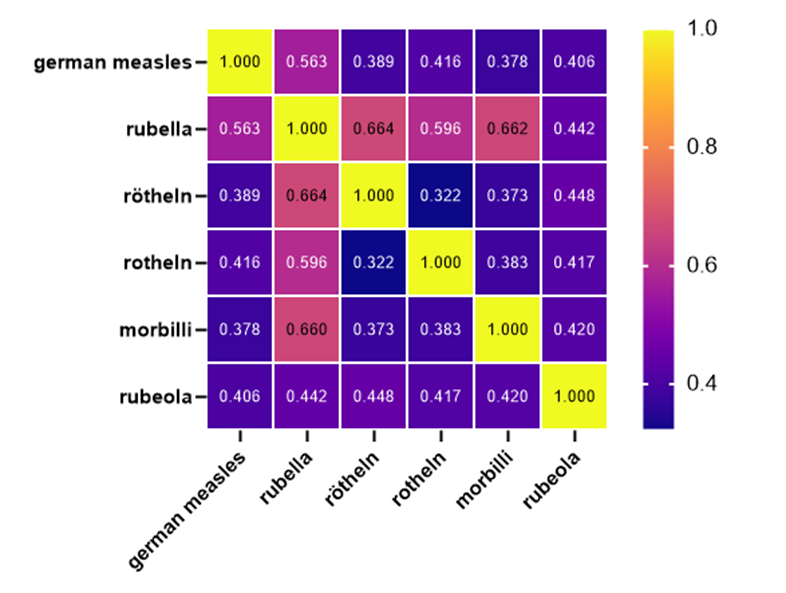
实验结论
并不能得到很好的效果(参数量达到了15亿,远超BERT,但在词语语义理解方面效果并不好)
BERT
BERT的全称是Bidirectional Encoder Representation from Transformers,即双向Transformer的Encoder,因为decoder是不能获得要预测的信息的。模型的主要创新点都在pretraining方法上,即用了Masked LM和Next Sentence Prediction两种方法分别捕捉词语和句子级别的representation。
bert-base-uncased:
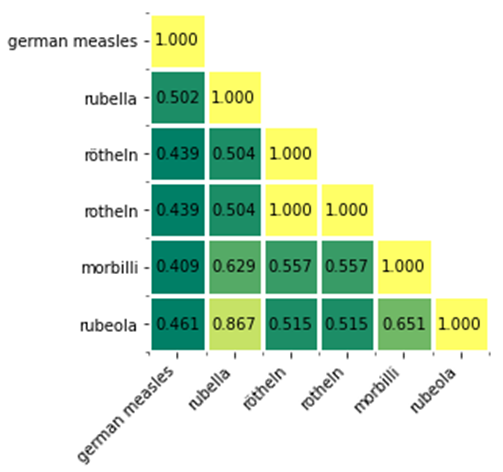
bert-base-multilingual-cased:
实验结论
(1)使用任何一种预训练模型(其中包含多语言模型,可以处理104/102种语言),都可以发现rötheln与rotheln的相似度均接近1
(2)尝试了BERT各种规格的模型,最后只发现最后一个预训练模型可以达到预期的效果,也就是rubella的相似度会更高,但是得到的相似度都在50左右,还有待提高
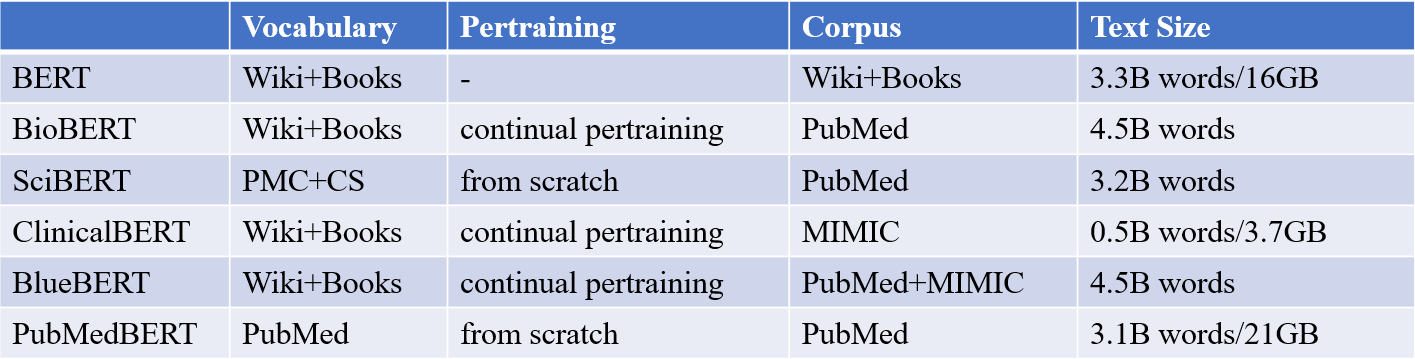
医学领域的BERT
直接将自然语言处理的进展应用到生物医学文本中,由于单词分布从一般领域语料库向生物医学语料库的迁移,往往会产生不令人满意的结果,所以此时需要专用于生物医学领域的模型。以下模型均使用BERT模型结构,只是在初始训练和预训练上与原始BERT存在差异。
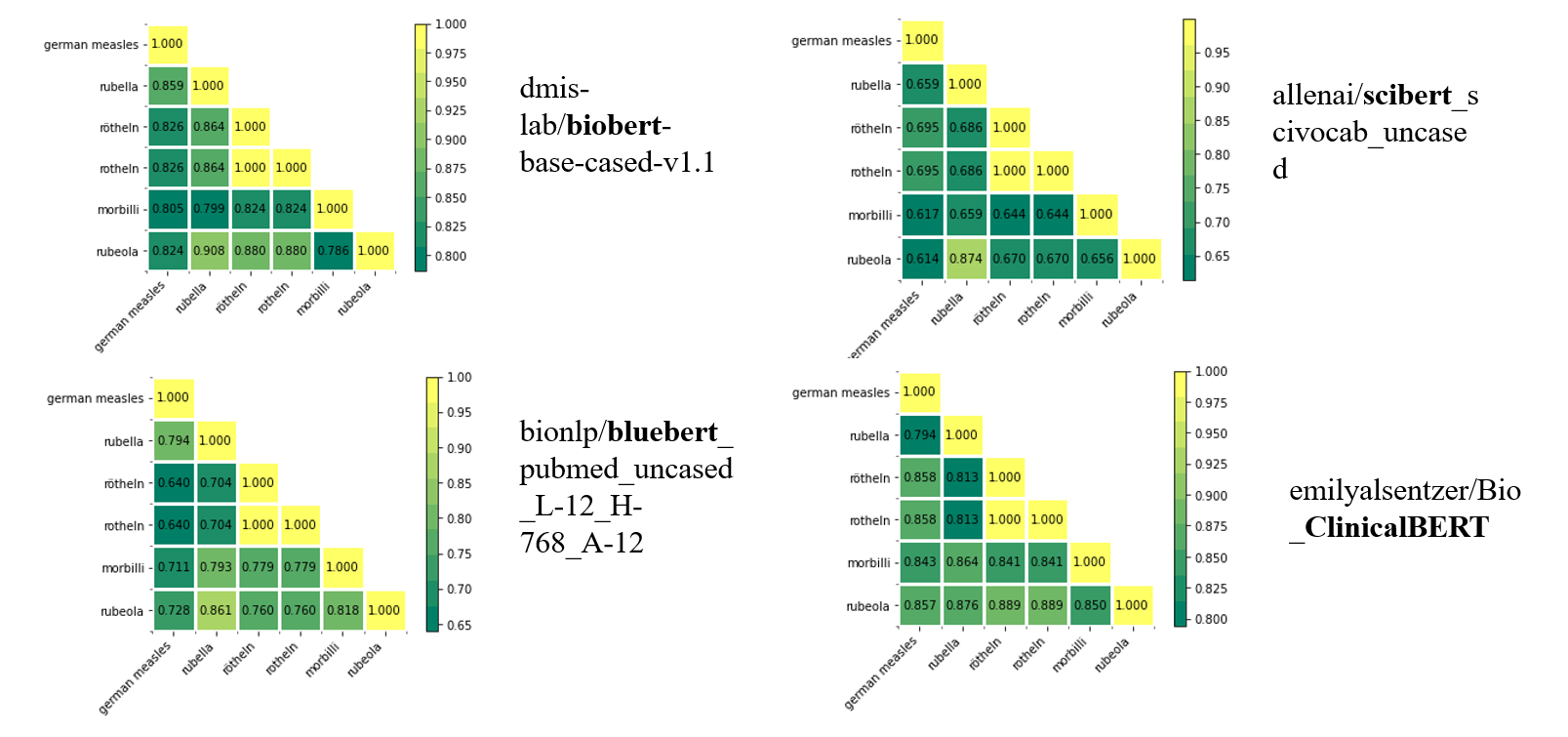
实验结果:
(1)PubMedBERT有着更好的效果。PubMedBERT提出了一种新的范例,该范例将从头开始完全只针对特定领域内的域内文本进行预训练,因此有了全新的词汇表,更小的切割率(尽量保持命名原来的word,而不是切个稀碎),最终得到的相似度结果更高。
(2)使用了医学领域的BERT模型后发现,进行过专业领域语料库训练模型的效果会更好,从头预训练的模型效果会更好