1 实验工具:webdriver
webdriver可以说是一个自动测试化工具,有时候会用在前端的自动化测试中方便前端人员编写自动化测试用例
编写前端自动化用例的首要原则即是模仿用户的习惯,在浏览器上进行各种“点击”、“下拉”、“滑动”等操作验证浏览器返回的响应是否与用户期望一致,而webdriver就是实现这些操作的工具
既然webdriver可以做到模仿用户进行浏览器的操作,那么必然也可以进行爬虫的实验,对比之前学过的xpath或是正则的爬虫,webdriver让我觉得可以处理更多网站的反爬机制,使用起来更加的灵活高效。
2 动机
实验的目的是为了获取Google Books上的文本数据,将段落级的文本数据下载之后进行各种NLP的数据处理,以便进行后续实验
- 例如:检索关键词为“virus”
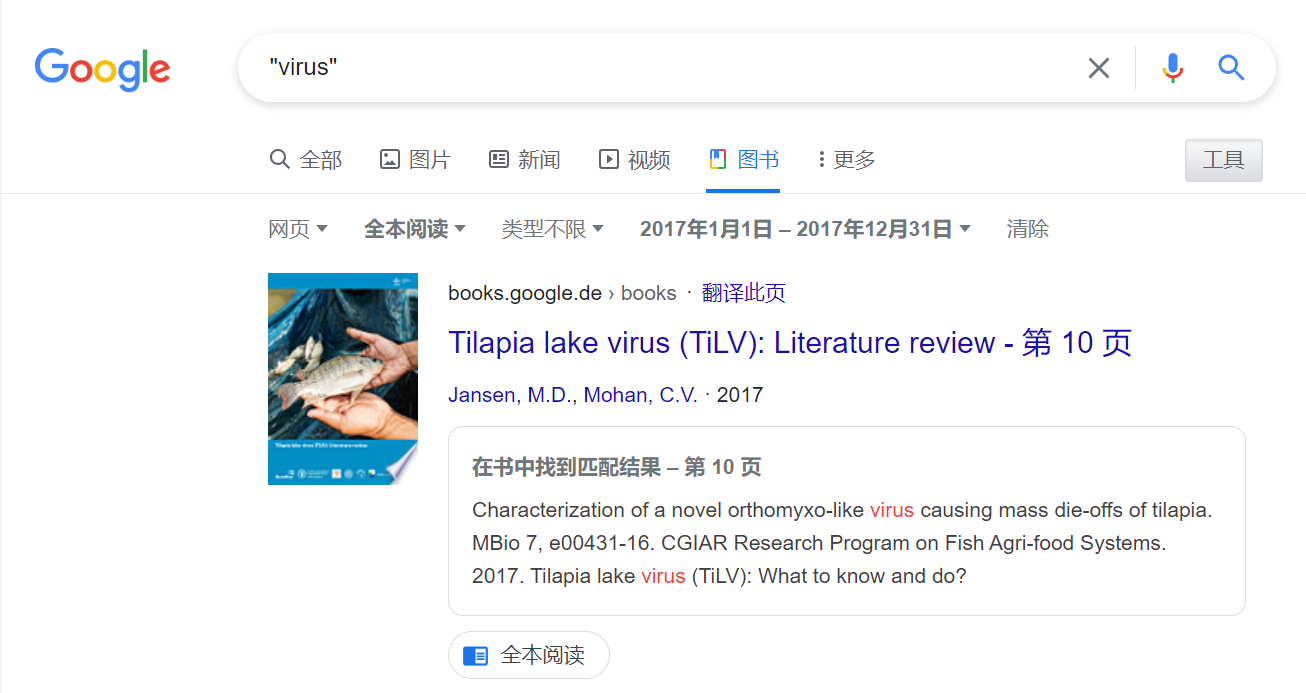
当检索到相关书籍后进入书籍的详情界面,最终希望的结果是把所有与检索关键词“virus”相关的语段都爬取下来,比如下图所示的这三个段落
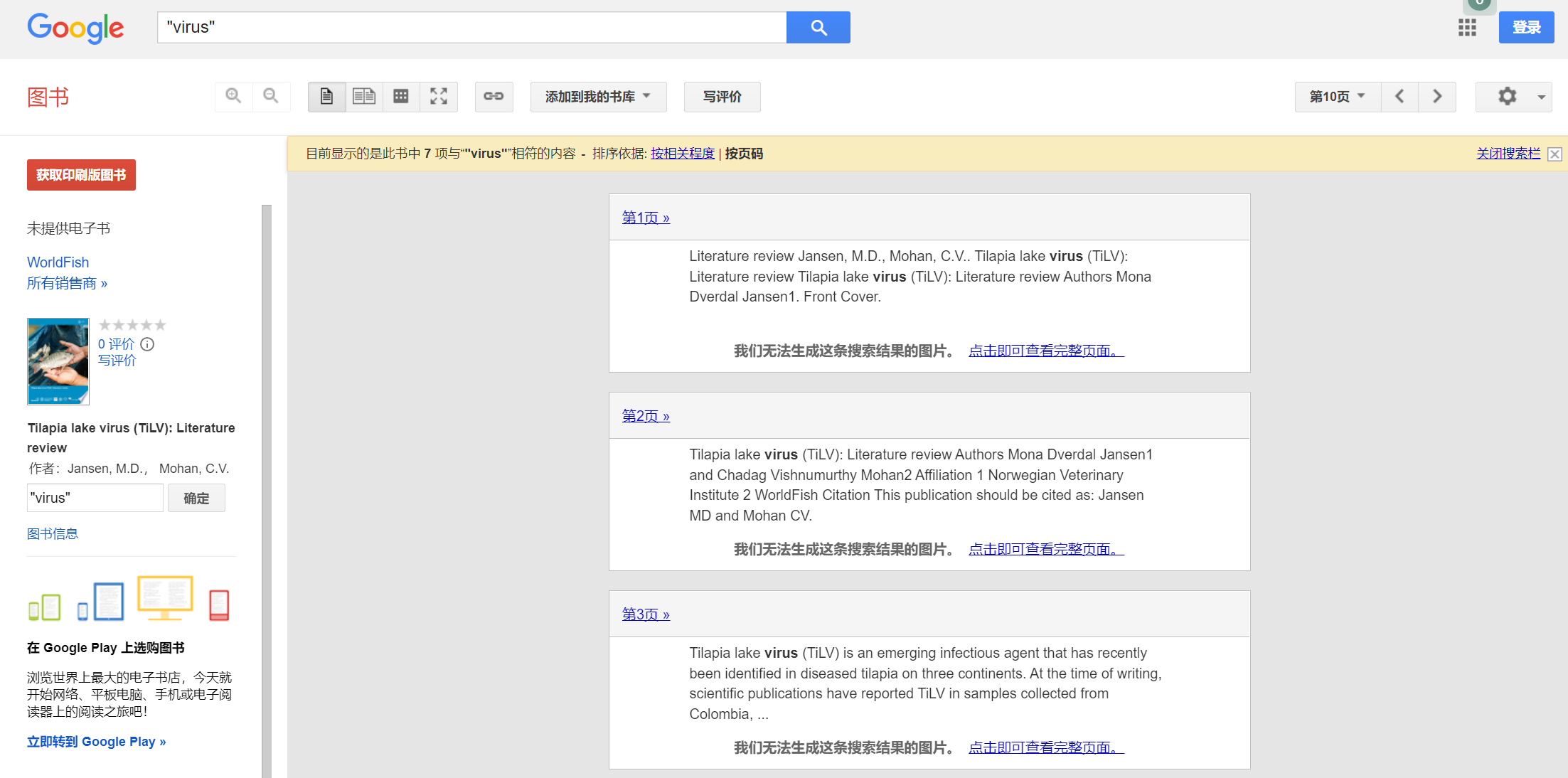
(本爬虫实验获取的均为网站公开数据,所有数据仅用于学习,远离非法爬虫从我做起![Z7QR[GM5_X75}X859H`XW]M](/upload/2022/05/Z7QR%5BGM5_X75%7DX859H%60XW%5DM.png) )
)
3 实验过程
把一些比较重要的反爬代码以及比较关键的步骤在下面罗列一下
3.1 随机使用useragent
User Agent是用户代理,简称 UA,它是一个特殊字符串头,使得服务器能够识别客户使用的操作系统及版本、CPU 类型、浏览器及版本、浏览器渲染引擎、浏览器语言、浏览器插件等。
代码里面使用的是fake_useragent,它可以自动生成很多的用户代理,但是此处有一个很大的坑❗❗❗
就是需要把Chrome浏览器的版本修改为101.0.4951.41,可能因为fake_useragent包的版本比较低,它生成的Chrome版本都是在40左右的,此时打开的Google Book界面每本书籍的信息是缺少出版时间这个信息的,而这次实验里面刚刚需要使用到这个出版时间,所以必须要修改Chrome的版本
from fake_useragent import UserAgent
def getUseragent():
myuseragent = UserAgent().chrome.split()
myuseragent[-2] = 'Chrome/101.0.4951.41' #必须要改成这个版本的,不然google的版本太低无法爬取
myuseragent = ' '.join(myuseragent)
# print(myuseragent)
return myuseragent
3.2 随机获取不同的google域名
谷歌网站对于爬虫的限制是更多的,特别是对一些异常的访问流量,我们在实验过程中很容易被网站识别出来,那么此时就可以使用不同的Google域名
我们最长使用的Googel域名是"www.google.com",但是很多人可能不知道谷歌还有很多其他的域名,比如根据不同的地理位置有不同的域名
这次实验中我选择了Googel将近200个域名,随机选择域名进行访问可以很好的掩盖爬虫的流量
import random
def google_main():
filepath = "./google main.txt"
googleUrl = [line.strip() for line in open(filepath, 'r', encoding='utf-8').readlines()]
url = random.choice(googleUrl) # 随机抽取
return url
3.3 使用webdriver中的定位工具点击按钮
使用浏览器打开一个新的谷歌域名时会要求用户对cookie的相关内容进行授权和同意
此时使用webdriver进行定位然后直接click()一下就很方便了
webdriver有很多定位的方式,具体可以参照下面这个文章:https://blog.csdn.net/yyyeyyyi_211/article/details/88849838
我使用的是xpath的定位方法
try:
driver.find_element_by_xpath("//button[@aria-label='同意 Google 出于所述的目的使用 Cookie 和其他数据']").click()
except:
print("success")
3.4 关闭webrtc
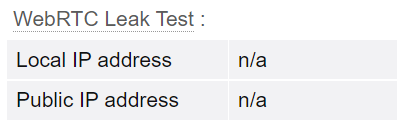
WebRTC是网页即时通信的缩写,是一个支持网页浏览器进行实时语音对话或视频对话的 API,但是就因为WebRTC 的存在导致就算代码中使用了代理,目标网站也能够得到用户的真实 IP
我们可以在这个网站中查看是否关闭了Webrtc,下图中出现两个n/a就说明已经成功的关闭了
https://browserleaks.com/ip
preferences = {
"webrtc.ip_handling_policy": "disable_non_proxied_udp",
"webrtc.multiple_routes_enabled": False,
"webrtc.nonproxied_udp_enabled": False
}
options.add_experimental_option("prefs", preferences)
3.5 使用socks5代理
我的代码里使用的是自己账号的socks5代理,如果要做到更好的伪装我们可以购买更多其他的代理IP然后在爬虫的过程中随机选择代理
SOCKS代理的主要优势是比较灵活。尤其是SOCKS5版本,SOCKS5代理除了支持TCP和UDP协议之外,还支持身份验证和服务器端域名解释等。除此之外,Socks5代理更注重文件传输的效率和速度。
options.add_argument("proxy-server=socks5://127.0.0.1:xxxx")
3.6 去掉webdriver痕迹
我们使用selenium+chromedriver启动chrome的时候,会在chrome的navigator以及document对象里注入一些属性,如果web服务器返回的js代码里有对这些属性的检测,那我们就会被识别为机器人在访问
想要去掉这个痕迹很简单,只需要增加一行标注即可
options.add_argument("disable-blink-features=AutomationControlled")
3.7 加载cookies中已经保存的账号和密码
我们在爬虫的过程中打开一个新的域名或者是打开新网站时可能需要登录用户名,那么此时我们可以选择用webdriver进行定位然后输入相关的账号密码信息,但其实我觉得在打开网站直接就直接加载原有的用户名信息会更加的方便
此处我就是在打开谷歌页面之前先加载了原先就存在电脑中的账号信息,这些账号信息的位置就在C:\Users\cy111\AppData\Local\Google\Chrome\User Data里面,我只要像下面一样设置一下user-data-dir,就可以在打开谷歌网页时直接到达登录状态
options.add_argument(r"user-data-dir=C:\Users\cy111\AppData\Local\Google\Chrome\User Data")
但是在使用时有一个需要注意的点就是要关闭其他已经打开的chrom网页,必须保证webdriver打开的新页面是chrom浏览器唯一一个页面❗❗❗
3.8 设置成代理的时区和地理位置
存在一个关闭了webrtc还是会被服务器识别为爬虫的情况,那就是浏览器的时区和地理位置
使用这个网站可以查找当前的时区和地理位置,https://whoer.net/zh

如果不在代码中进行修改就会发现就算开了代理,但是当地时间和系统时间不一样还是会被反爬给发现
import requests
def get_timezone_geolocation(ip):
url = f"http://ip-api.com/json/{ip}"
response = requests.get(url)
return response.json()
res_json = get_timezone_geolocation("xxx.xxx.xxx.xxx")
# print(res_json)
geo = {
"latitude": res_json["lat"],
"longitude": res_json["lon"],
"accuracy": 1
}
tz = {
"timezoneId": res_json["timezone"]
}
driver.execute_cdp_cmd("Emulation.setGeolocationOverride", geo)
driver.execute_cdp_cmd("Emulation.setTimezoneOverride", tz)
3.9 总结
最后爬虫的相关代码脚本可以在此处查看:
https://github.com/YaChen8/web-crawler_GoogleBooks
这个实验也可以说是让我对webdriver更加的熟悉了解了,以及原先可能存在的就算是设置了代理也会被反爬的问题也得到了很好的解决
爬虫的速度不算太快,但是运行起来还是算稳定的,因为开着webdriver网页测试花费了一定的时间,如果想要缩短时间的可以设置谷歌浏览器的页面无可视化,或是采用其他方法
options.add_argument('--headless')
options.add_argument('--disable-gpu')
4 待改进
当数据爬取到2万条时会出现Google的人机身份验证
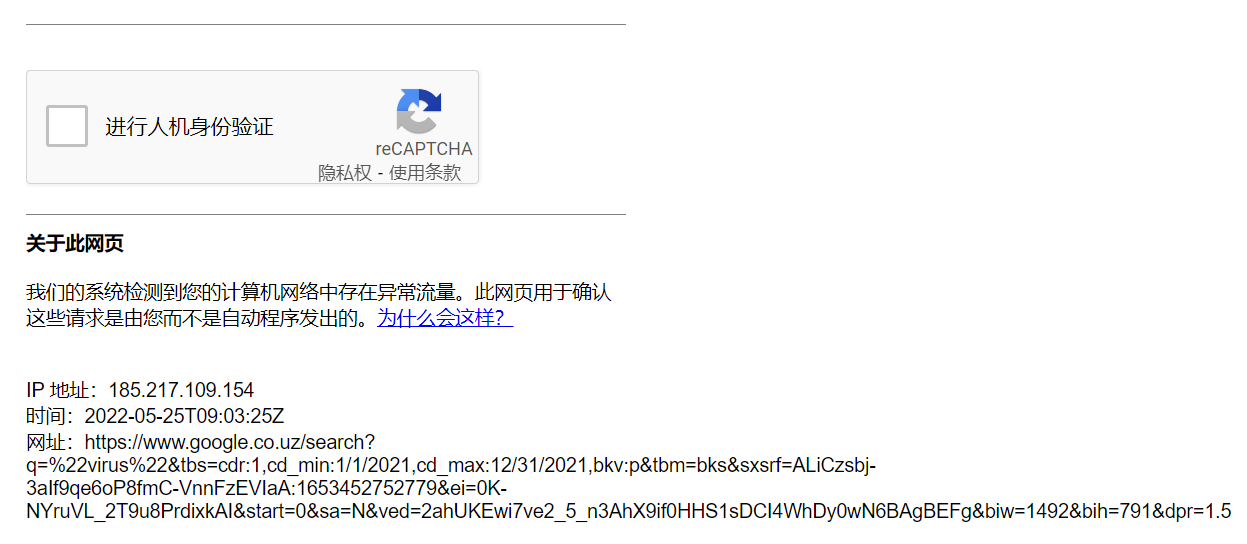
这个不是单纯的点击某个按钮就能通过验证的
在网上看见了一个比较好的做法能解决这个人机验证的麻烦:
https://www.likecs.com/show-804855.html
使用了一个第三方平台,但是需要付费,并且在我这个实验里爬取需要的数据量不算非常多,所以就暂时码着以后或许会有用