1、项目实验介绍
这次的建模项目是某一年的华为杯研究生数学建模竞赛,相关的题目背景如下。主要讲的是汽油辛烷值的建模:
汽油清洁化重点是降低汽油中的硫、烯烃含量,同时尽量保持其辛烷值。
辛烷值(以RON表示)是反映汽油燃烧性能的最重要指标,辛烷值每降低1个单位,相当于损失约150元/吨。
某石化企业的催化裂化汽油精制脱硫装置运行4年,积累了大量历史数据,其汽油产品辛烷值损失平均为1.37个单位,而同类装置的最小损失值只有0.6个单位。
因此能够利用数据挖掘技术来解决化工过程中建模问题
2、数据集介绍

总共是有325个样本,且每个样本包含354个操作变量,其中285号和313号样本的数据需要进行额外的处理,是实验的其中一个目标
其中原料及产品的辛烷值是重要的建模变量,该数据采集频次为每周2次。
由于辛烷值的测定数据相对于操作变量数据而言相对较少,而且辛烷值的测定往往滞后,因此确定某个样本的方法为:以辛烷值数据测定的时间点为基准时间,取其前2个小时的操作变量数据的平均值作为对应辛烷值的操作变量数据。
3、实验目标
依据从催化裂化汽油精制装置采集的325个数据样本(每个数据样本都有354个操作变量),通过数据挖掘技术来建立汽油辛烷值(RON)损失的预测模型,并给出每个样本的优化操作条件,在保证汽油产品脱硫效果(欧六和国六标准均为不大于10μg/g,但为了给企业装置操作留有空间,本次建模要求产品硫含量不大于5μg/g)的前提下,尽量降低汽油辛烷值损失在30%以上。
总共有五个待解决的问题(绿色的标注为解题的大致思路):
- 问题1

- 问题2

- 问题3

- 问题4

- 问题5

4、实验简述
这部分技术路径还是很明确的,首先根据要求进行数据清洗,接着使用一些方法对特征变量进行筛选和降维。最终使用降维后的特征值建立辛烷的预测模型,问题四是一个优化问题,可以使用遗传算法或是粒子群算法来构建,相应的,最后一问就是对优化过程进行一个可视化
前两问使用python,后三问使用Matlab
相关代码可以在colab链接中找到:
https://drive.google.com/drive/folders/1-55AHizH-9_qwyuA2G8rV8UElcyS1MeA?usp=sharing
实验使用的数据集已经上传百度网盘:
链接:https://pan.baidu.com/s/1E941SksmwKkuzTkIqjbc2w?pwd=qk47
5、实验结果
-
模型建立的变量
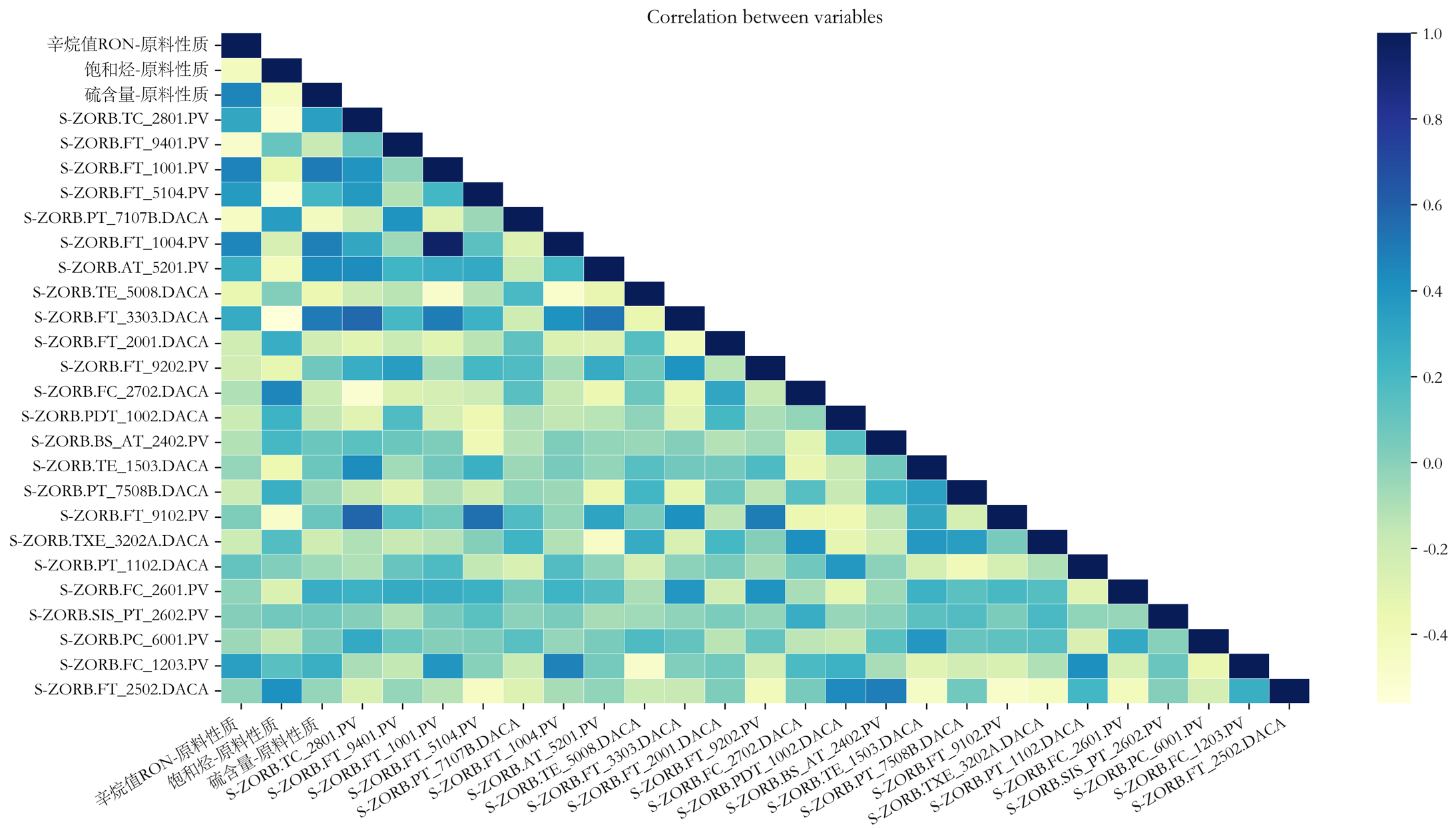
-
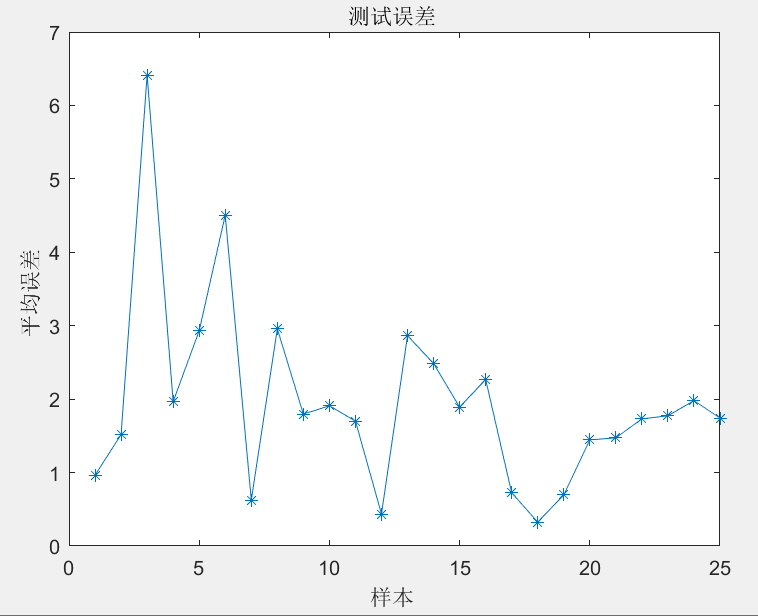
模型误差曲线:
该神经网络的迭代次数设置为1000,训练目标设置为0.000001,隐含层数设置为 90,学习率设置为 0.4。
-
真实值和拟合 曲线:
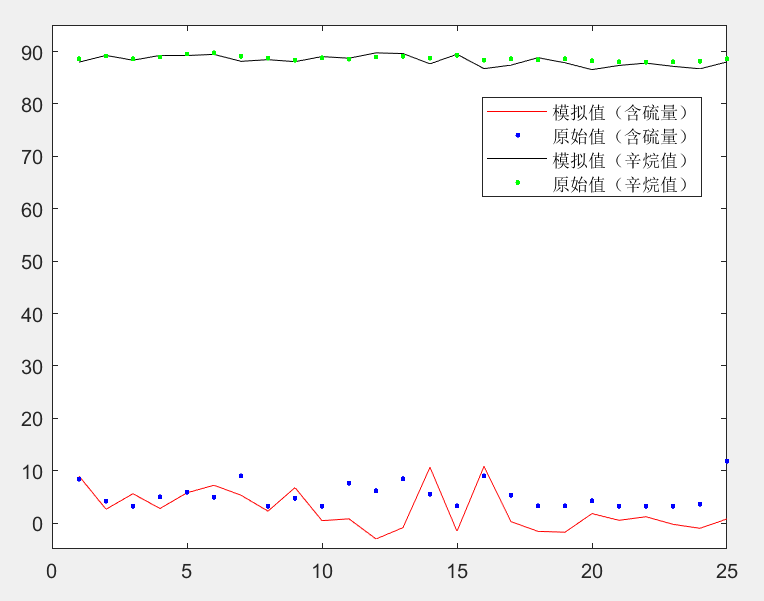
所示,从数据中看出拟合度良好,预测精度拟合效果较好 -
遗传参数设定(以种群规模为例)

确定种群规模:在最初实验中,种群规模分别设置为50,100,150,200,300. 其他遗传参数交叉率设置为0.5,变异率设置为0.05,最大迭代次数设置为500。按照设定的种群规模分别进行 5 次运算,对比5 次运算各代最优个体均方差的平均值。从图中的计算结果不难看出,当种群规模为50 时个体的误差最小,因此本研究种群规模设置为50。 -
不同操作变量变化对产品硫含量和辛烷值影响的曲线:(此处以干气出装置温度变换为例)
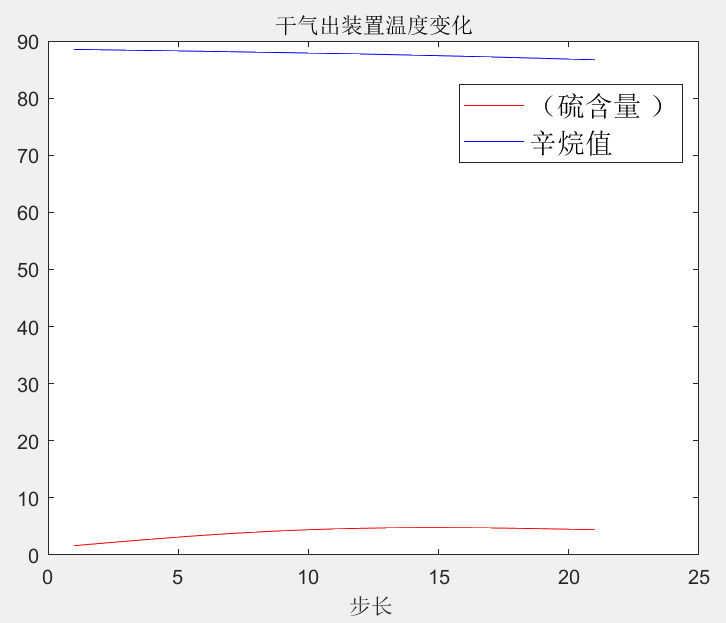
从图可以看出 干气出装置温度 增加对产成品的辛烷值 表现出 负向的影响, 对产成品的硫含量影响不大