在处理高维数据集时,我们可能会遇到聚类方法的问题。特征选择是监督学习的一种众所周知的技术,但对于无监督学习(如聚类)方法来说却少之又少。在这里使用一个相对简单的贪心算法来对 Kaggle 上的欧洲数据集执行变量选择。
算法步骤
- 确保变量是数字且经过缩放的,例如使用 StandardScaler() 及其 fit_transform() 方法
- 选择要保留的最大变量 ( maxvars )、最小和最大簇数 ( kmin和kmax ) 并创建一个空列表:selected_variables。
- 从 kmin 循环到 kmax。然后,依次使用每个变量,使用 K 均值记录每个变量组合和聚类数量(从 kmin 到 kmax)的轮廓值。
- 选择给出最大轮廓值的变量,将其添加到selected_variables并将其从要测试的变量列表中删除。
- 通过使用selected_variables列表并依次添加每个剩余变量来重复 2 和 3 中的过程,直到达到某个停止标准(在本例中为要保留的变量数maxvars)。
具体代码执行
定义并初始化一些变量
maxvars=3
kmin=2
kmax=8
kmeans_kwargs = {"init": "random","n_init": 20,"max_iter": 1000,"random_state": 1984}
cut_off=0.5
# We also define a cols variables containing a list of all features:
cols=list(df.columns)
# We also set a list and a dictionary to store the silhouette values
# for each number of clusters tested so we can choose the k value
# maximising the silhouette score, with its corresponding features
results_for_each_k=[]
vars_for_each_k={}
然后,创建三个嵌套循环,外部循环遍历k的值(簇数)。然后有一个 while 循环检查保留变量的数量是否低于maxvars设置的阈值。selected_variables列表将保存保留的功能名称。结果列表将保存每个变量的轮廓值。
for k in range(kmin,kmax+1):
selected_variables=[]
while(len(selected_variables)<maxvars):
results=[]
selected_variables=[]
print(k)
while(len(selected_variables)<maxvars):
results=[]
内部循环会一一遍历所有特征,将它们添加到已选择的变量(如果有)中,并评估轮廓值。然后它选择获得最高值的变量并将其添加到selected_variables列表中。
for col in cols:
scols=[]
scols.extend(selected_variables)
scols.append(col)
kmeans = KMeans(n_clusters=k, **kmeans_kwargs)
kmeans.fit(df[scols])
results.append(silhouette_score(df[scols], kmeans.predict(s)))
# We identify the best variable, add it to our list and remove it
# from the list of variables to be tested on the next iteration
selected_var=cols[np.argmax(results)]
selected_variables.append(selected_var)
cols.remove(selected_var)
然后可以在循环中更新该特定 k 值的变量列表和分数。
results_for_each_k.append(max(results))
vars_for_each_k[k]=selected_variables
最后,三个循环运行后,我们可以确定 k 和变量的最佳组合,拟合模型并绘制它。
best_k=np.argmax(results_for_each_k)+kmin
selected_variables=vars_for_each_k[best_k]
kmeans = KMeans(n_clusters=best_k, **kmeans_kwargs)
kmeans.fit(df_[selected_variables])
clusters=kmeans.predict(df[selected_variables])
结果
根据人口、财富和犯罪率划分的 2 个国家组的最终结果:
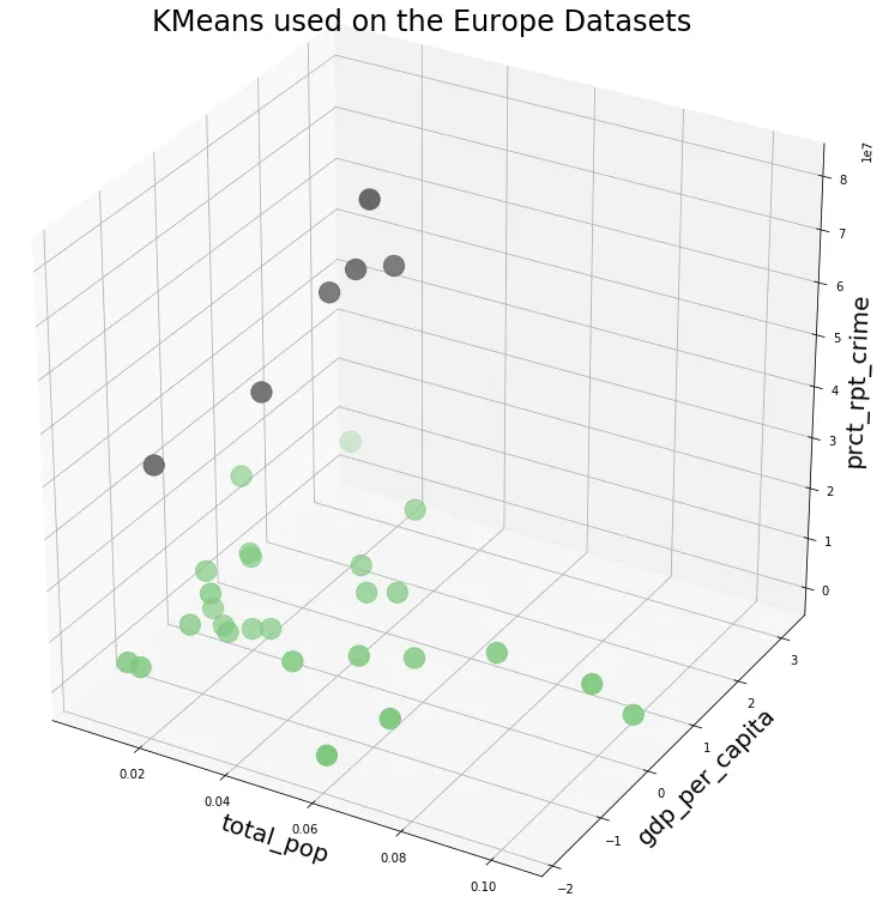
如果选择 3 个簇,就会得到不同的选择:
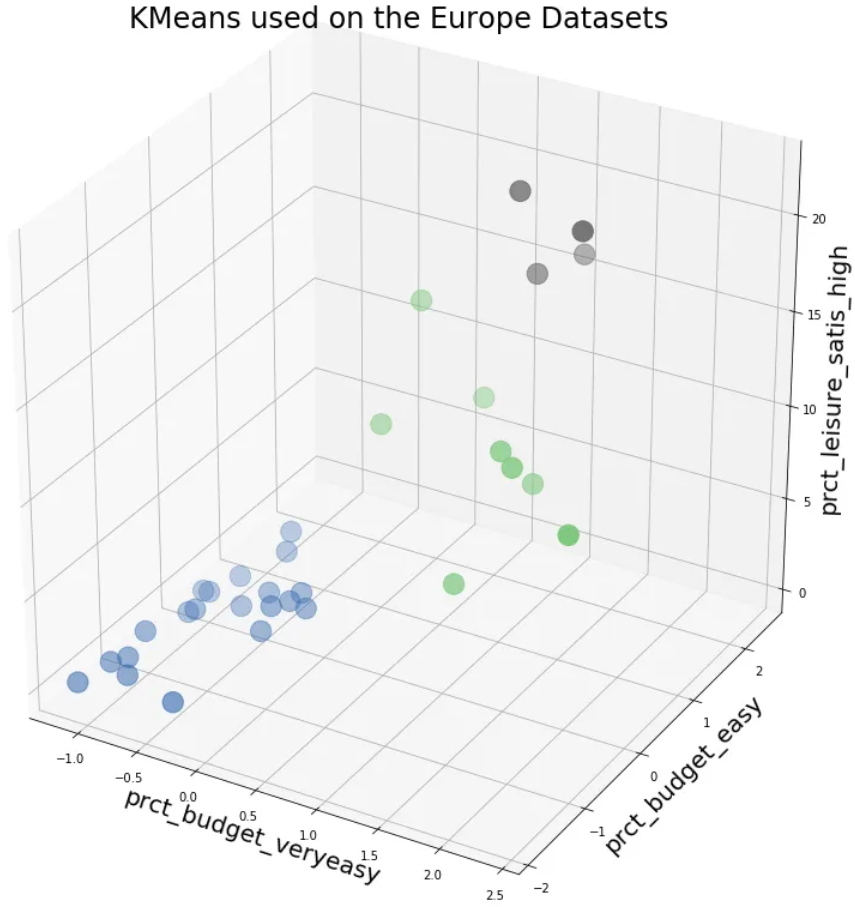
每组国家的一些示例:
Cluster1: Iceland, Switzerland, Belgium, Germany, Luxembourg, Netherlands, Austria and United Kingdom
Cluster 2: Greece, Spain, France, Croatia, Italy, Cyprus, Latvia, Lithuania, Hungary, Malta, Poland, Portugal
Cluster 3: Norway, Denmark, Finland and Sweden
完整代码
scaler = StandardScaler()
df=scaler.fit_transform(df)
kmeans_kwargs = {"init": "random","n_init": 20,"max_iter": 1000,"random_state": 1984}
cut_off=0.5
maxvars=3
kmin=2
kmax=8
cols=list(df.columns)
results_for_each_k=[]
vars_for_each_k={}
for k in range(kmin,kmax+1):
selected_variables=[]
while(len(selected_variables)<maxvars):
results=[]
for col in cols:
scols=[]
scols.extend(selected_variables)
scols.append(col)
kmeans = KMeans(n_clusters=k, **kmeans_kwargs)
kmeans.fit(df[scols])
results.append(silhouette_score(df[scols], kmeans.predict(df[scols])))
selected_var=cols[np.argmax(results)]
selected_variables.append(selected_var)
cols.remove(selected_var)
results_for_each_k.append(max(results))
vars_for_each_k[k]=selected_variables
best_k=np.argmax(results_for_each_k)+kmin
#you can also force a value for k
#best_k=3
selected_variables=vars_for_each_k[best_k]
kmeans = KMeans(n_clusters=best_k, **kmeans_kwargs)
kmeans.fit(df[selected_variables])
clusters=kmeans.predict(df[selected_variables])
%matplotlib inline
fig = plt.figure(figsize=(15,15))
#plt.rcParams['font.size'] = 22
ax = plt.axes(projection="3d")
z_points = df_[selected_variables[0]]
x_points = df_[selected_variables[1]]
y_points = df_[selected_variables[2]]
f1=ax.scatter3D(x_points, y_points, z_points, c=clusters,cmap='Accent',s=300);
ax.set_xlabel(selected_variables[0],fontsize = 20)
ax.set_ylabel(selected_variables[1],fontsize = 20)
ax.set_zlabel(selected_variables[2],fontsize = 20)
ax.legend(clusters)
plt.title('KMeans used on the Europe Datasets',fontsize = 24)
plt.show()