一、Google Books Ngram Viewer介绍
https://books.google.com/ngrams
谷歌的这个项目提供了谷歌图书扫描并数字化的部分图书(占人类出版书籍的4%)的Ngram数据。你可以查询从1500年到2019年所有出版物中一个词汇出现的频率变化曲线。
数据虽然简单但是仔细窥探背后依旧会有值得的信息
最终呈现的曲线不仅仅是一个普通的曲线,通常我们都可以从中得到更多数据背后的深层次含义,下面是一些Google Books Ngram Viewer有意思的用法。
1、从中获取英语语法的常见用法
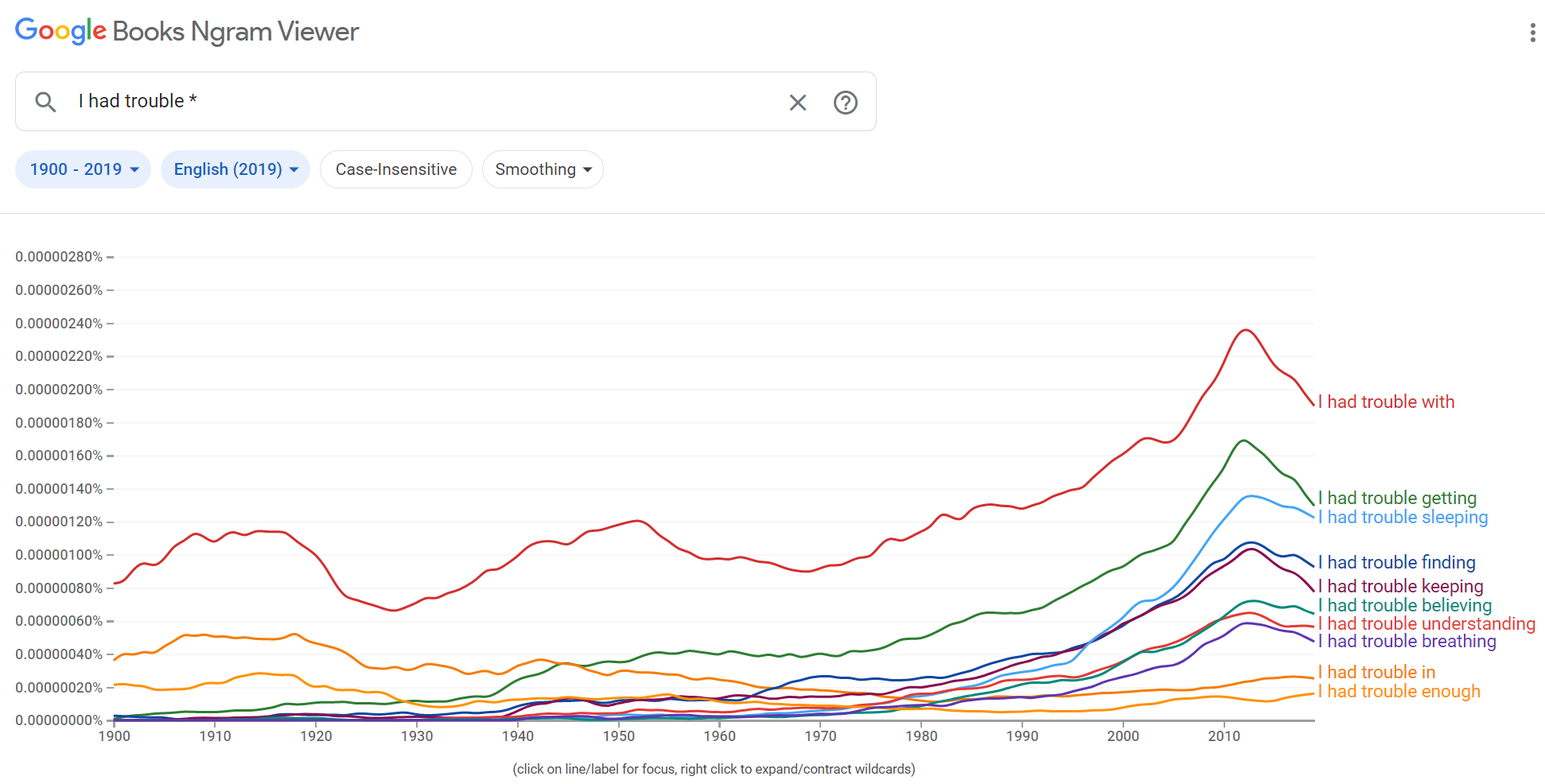
搜索关键词,网页会自动进行匹配,最后得到I had trouble的一些常见搭配用法,在写作的时候我们就可以以此作为纠错的依据,一般使用频率较高的就是正确的语法搭配,当然也可能出现广泛用错词组的现象,这个功能很适合英语学习者进行借鉴。
2、了解事物发展历史

这个世界上时时刻刻发生着各种的病毒感染,当一个疾病开始蔓延必然会带来各地人们的广泛讨论,因此通过疾病单词的使用词频我们或许可以看见背后疾病爆发和发展的情况。
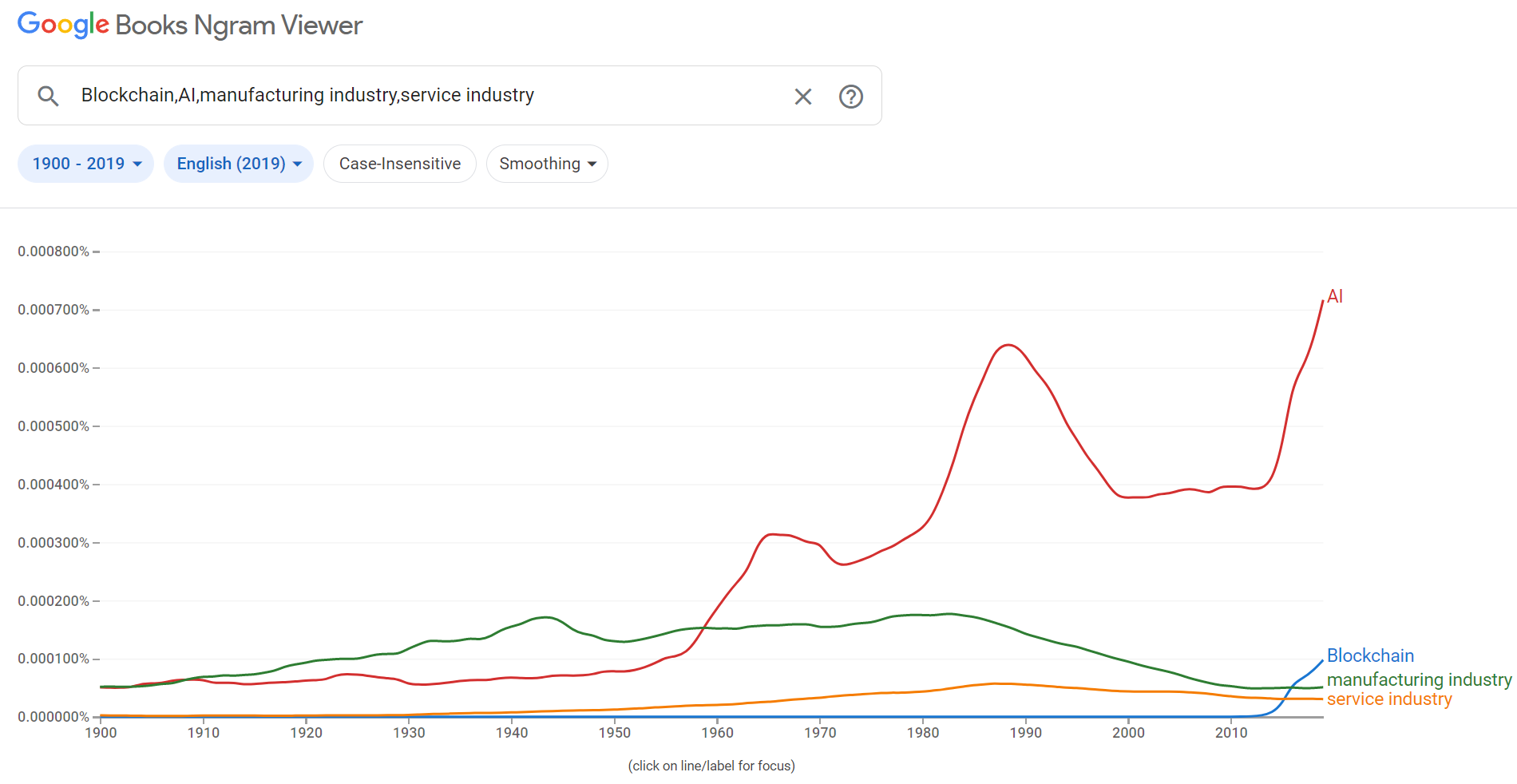
从这个曲线也可以看出AI的发展趋势是极快的而且在当下占据的很高的话题度,区块链的话题在2013年热度逐渐提升,在未来有着极大的发展前景,由此可见这些与人工智能相关的技术及产业会逐渐成为未来发展的主导;然而像制造业和服务业的使用词频在逐年下降,说明社会不断发展制造业等开始走下坡路,传统行业开始没落。
3、与机器学习和人工智能相结合
除了上述简单的曲线观察,GBNV带来的时间序列数据也可以使用机器学习或是人工智能的算法模型进行处理,进而得到更复杂的统计学细节,比如下面的这些图就是通过算法模型处理Google Books Ngram Viewer的数据得到的:
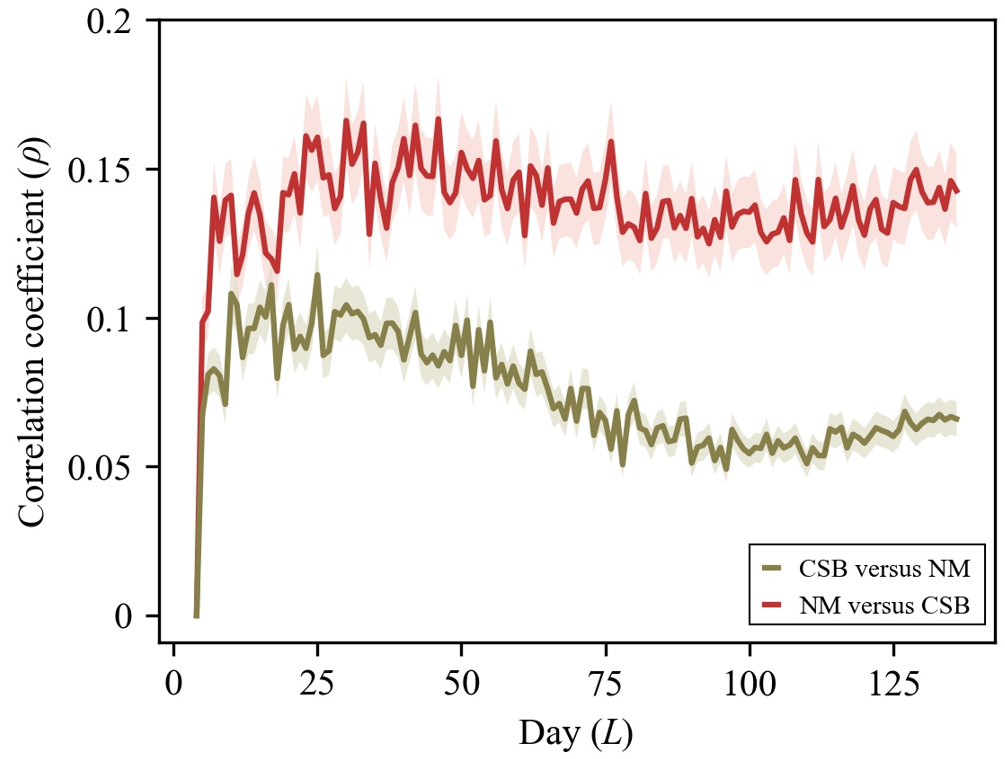
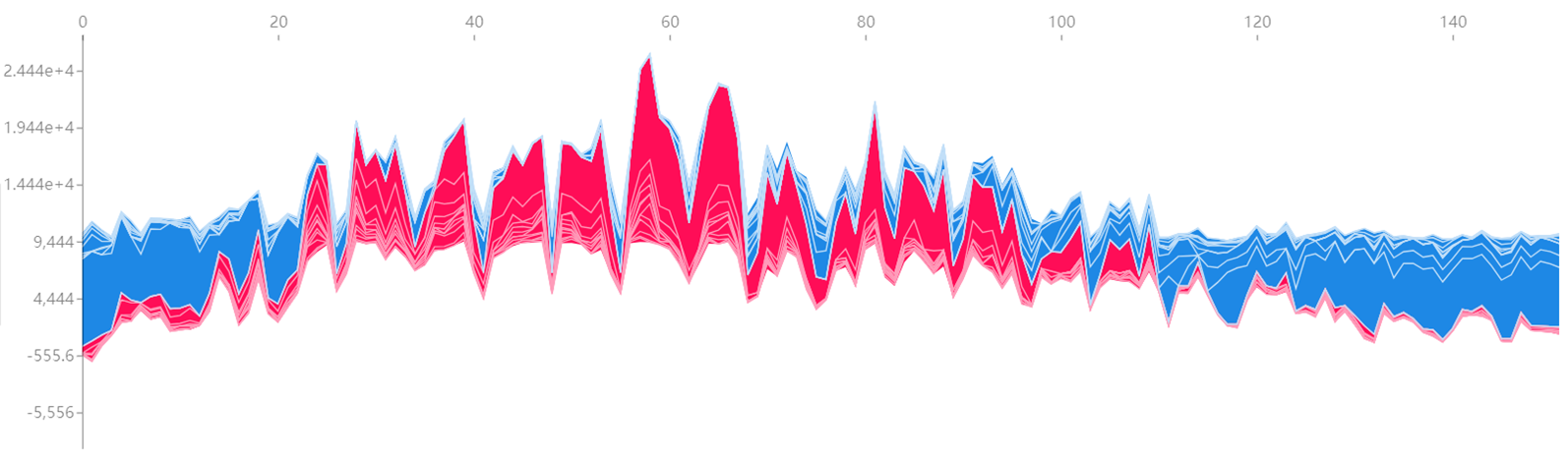
模型算法具体细节篇幅有限就不详细阐述了。
二、Google Books Ngram Viewer数据下载工具
Google Books Ngram Viewer网页的数据那么有研究价值,那么就很有必要将数据下载下来,但是官方的网页没有可以下载原始时间序列数据的地方,所以就在Github上找到了一个可以获取网页词频时间序列数据的工具,使用的方法就是简单的爬虫,由于代码是七年前上传的已经完全过时且没法适配了,所以对全部的代码进行了改动,并且调整了一些细节。
部分更新内容:
-
原本的代码版本不支持python3,修改相关的语法
-
更新了语料库的年份,全部更新至2019年
原版本:

现版本:

-
更新了默认查询的时间,现在最长可以支持查询1500年-2019年,而且去掉保存过程存在的无效空行
原版本:
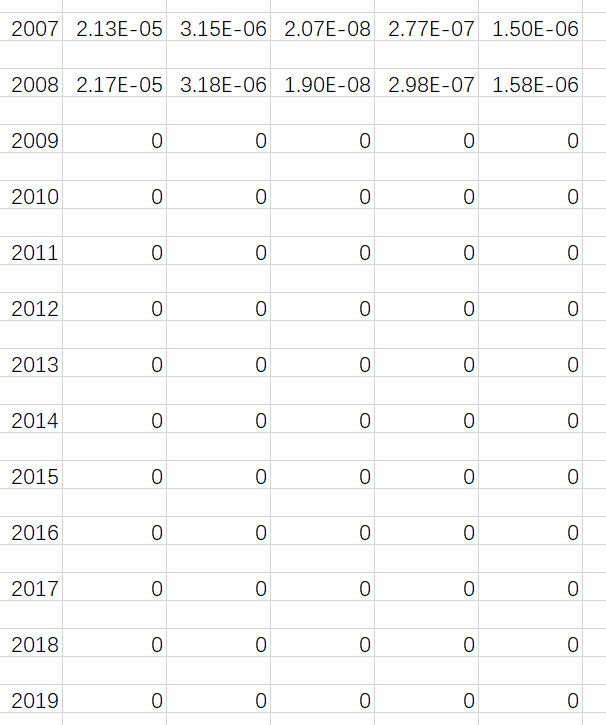
现版本:

三、下载工具用法
更新代码下载地址:
https://github.com/YaChen8/NgramScript/tree/NgramScript-python3
Example usage:
下载所有代码后在setup.py文件夹位置按住Shift键同时鼠标右击,点击“在此处打开Powershell窗口”
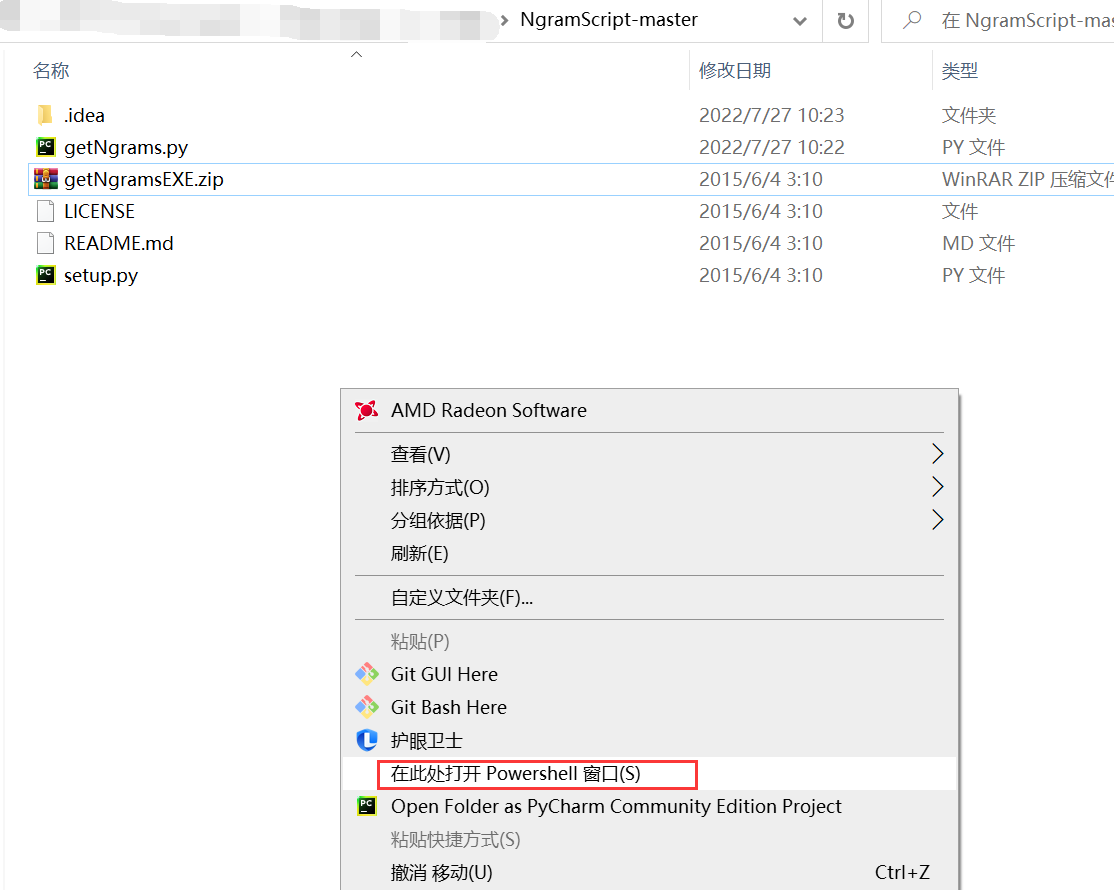
打开代码行界面后输入下方的代码然后按回车,运行完对应的代码行后会在setup.py的文件位置输出保存的结果
python .\getNgrams.py virus,toxin,vira,virion,venom -corpus=eng_2019 -startYear=1900 -endYear=2019 -smoothing=0 -csv -quit -noprint
python .\getNgrams.py [想要查询的词组] -corpus=[语料库] -startYear=[查询开始年份] -endYear=[查询结束年份] -smoothing=[曲线平滑参数] -csv -quit -noprint
Flags:
- -corpus=检索使用的语料库 [默认: eng_2019]
具体参数可以去该网页查找http://books.google.com/ngrams/info. - -startYear=查询开始年份 [默认: 1500]
- -endYear=查询截至年份 [默认: 2000]
- -smoothing=曲线平滑系数 [默认: 3]
- -nosave 该参数表示不保存
- -csv 该参数表示保存为csv表格
- -noprint 该参数表示为结果不在运行界面输出
- -help
- -quit 添加这个参数后运行完代码直接退出