最近在整理毕业论文可视化的数据,这是一个JACS3.0学科分类系统的数据。
JACS系统由HESA(高等教育统计局是英国负责收集、分析及传播高等教育信息的官方机构)和UCAS(英国全国大学的统一学生申请机构)共同拥有和维护。
所有JACS 3.0主题代码都由一个字母后跟三个数字组成,第一个数字是非零的。首字母标识学科组,例如F表示物理科学。首字母和紧随其后的数字表示主要学科,例如F5天文学。第二个和第三个数字更精确地识别对象,例如F52空间和行星科学。更精确的F521空间科学和F522行星科学。
F5表示所有天文学和天文学中的总数,而不是F500。同样,F52指的是整个空间和行星科学。而不是F520。
数据总共有一千多条,导师希望我把数据画成一个径向树状图的形式,类似下面这个图,因为学科分类是涉及层次等级的,所以用这种树形图也可以很清晰的看出学科所处的等级

查找了一下pyecharts可以实现这个功能,数据的形式使用的是json格式的,所以这就需要我把原先的excel列表格式数据转化成json格式的数据,所以就写了两个脚本实现了这个这个功能。
首先原始数据的格式如下:
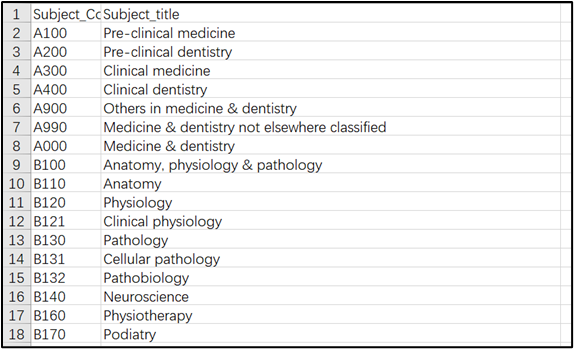
1、先用脚本将原先第一列的学科编码进行等级分割
import pandas as pd
# Load the data
data = pd.read_csv('JACS3_Vocab.csv')
# Pre-process the data
data.columns = ['code', 'subject']
data['Level_1'] = data['code'].str[0]
data['Level_2'] = data['code'].str[:2]
data['Level_3'] = data['code'].str[:3]
data['Level_4'] = data['subject']
# Define a dictionary for Level_1 replacements
replacement_dict = {
"A": "Medicine and Dentistry",
"B": "Subjects Allied to Medicine",
"C": "Biological Sciences",
"D": "Veterinary Sciences, Agriculture and related subjects",
"F": "Physical Sciences",
"G": "Mathematical Sciences",
"H": "Engineering",
"I": "Computer Sciences",
"J": "Technologies",
"K": "Architecture, Building and Planning",
"L": "Social Studies",
"M": "Law",
"N": "Business and Administrative Studies",
"P": "Mass Communication & Documentation",
"Q": "Linguistics, Classics and Related Subjects",
"R": "European Languages, Literature and Related Subjects",
"T": "Eastern, Asiatic, African, American and Australasian Languages, Literature and Related Subjects",
"V": "Historical and Philosophical Studies",
"W": "Creative Arts and Design",
"X": "Education"
}
# Replace the values in Level_1
data['Level_1'] = data['Level_1'].replace(replacement_dict)
# Add the Weight column
data['Weight'] = 1
# Re-order the columns
data = data[['code', 'Level_1', 'Level_2', 'Level_3', 'Level_4', 'Weight']]
# Save the processed data to a new CSV file
data.to_csv('Processed_JACS3_Vocab_with_weight.csv', index=False)
最终得到的数据如下所示:
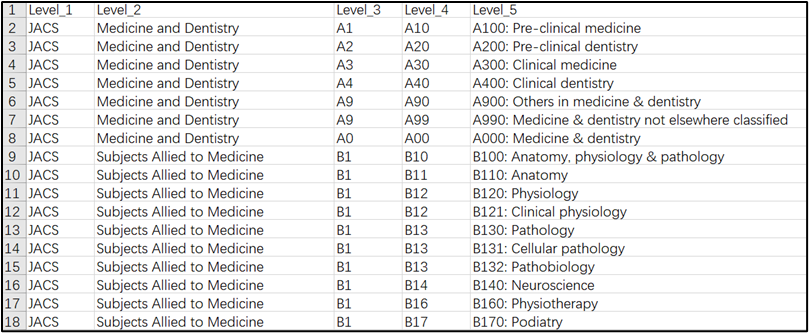
2、接着将上面划分完等级的数据修改为json格式
import pandas as pd
import json
def find_node(name, parent):
"""Find a node in the parent."""
if "children" in parent:
for node in parent["children"]:
if node["name"] == name:
return node
return None
def add_node(name, value, parent):
"""Add a node to the parent."""
node = find_node(name, parent)
if node is None:
node = dict(name=name, value=value)
parent.setdefault("children", []).append(node)
return node
def process_csv_to_json(csv_path, json_path):
# Load the CSV data
csv_data = pd.read_csv(csv_path)
# Initialize the root
tree = dict(name="JACS")
# Iterate over each row in the dataframe and add to the tree
for _, row in csv_data.iterrows():
level1, level2, level3, level4, level5, value = row
node1 = add_node(level1, None, tree)
node2 = add_node(level2, None, node1)
node3 = add_node(level3, None, node2)
node4 = add_node(level4, None, node3)
node5 = add_node(level5, value, node4)
# Write the tree to a JSON file
with open(json_path, 'w') as f:
json.dump(tree, f)
process_csv_to_json('input.csv', 'output.json')
最终得到的数据如下所示:
3、下面是最终用处理后的json数据画出来的径向树状图,基本已经实现了需求,图上只能查看前2个等级的数据,不过保存后的html可以查看到最终的根目录,后期在这个图上再修改可视化

下面是用pyecharts实现径向树状图的代码,主要比较复杂的部分是其中用JavaScript的递归函数来处理了一级类别中较长标签的换行问题,真是研究了很久,因为好像提供的代码中没法直接来设置这个标签长度的特征,所以只能使用js来调整
from pyecharts.charts import Bar
from pyecharts import options as opts
from pyecharts.charts import Tree
from pyecharts.render import make_snapshot
from snapshot_selenium import snapshot
import asyncio
from aiohttp import TCPConnector, ClientSession
from pyecharts.commons.utils import JsCode
import json
from pyecharts.options import LineStyleOpts
txt_file = "JACS"
f_json = open(txt_file + ".json")
data = json.load(f_json)
# print(data)
tree = (
Tree(init_opts=opts.InitOpts(width="7000px", height="7000px"))
.add(
series_name="",
data=[data],
pos_top="5%", # 调整树形图在画布中的位置
pos_bottom="5%",
pos_left="10%",
pos_right="10%",
layout="radial", # 径向布局是指以根节点为圆心,每一层节点为环
symbol="emptyCircle", # 标记的图形
symbol_size=60, # 标记的大小
initial_tree_depth=2,
label_opts=opts.LabelOpts(
color="black",
position="inside",
# horizontal_align="right",
# vertical_align="middle",
font_size=80, # 增加标签大小
# 使用JavaScript的递归函数来处理
formatter=JsCode("""
function(params) {
function splitWords(words) {
if (words.length > 4) {
return words.slice(0, 4).join(' ') + '\\n' + splitWords(words.slice(4));
} else {
return words.join(' ');
}
}
return splitWords(params.name.split(' '));
}
"""),
),
leaves_label_opts=opts.LabelOpts(
color="black",
position="left",
horizontal_align="right",
vertical_align="middle"
),
itemstyle_opts=opts.ItemStyleOpts( # 节点黑色边框
border_color="black",
border_width=5,
),
)
.set_global_opts(
tooltip_opts=opts.TooltipOpts(trigger="item", trigger_on="mousemove"),
)
)
make_snapshot(snapshot, tree.render(txt_file + "_tree2.html"), txt_file + "_tree2.png")